

【この記事でできること】
- AIにPythonコードを書かせるコツ
- 製造日報(ダミー)のCSVデータを作成
- スプレッドシートで日報フォーマットへ自動転記
- Apps ScriptでPDFを一括生成
ちなみに今回は検証用の日報ダミーデータの作成用途ですが、少し応用すると
- 注文情報一覧(表)から注文書への転記➔PDF化
- 見積情報一覧(表)から見積書への転記➔PDF化
こういう用途でも使えそうかなと思っています。
一度設定すると、一覧表からフォーマットに転記して、PDF化するという作業がかなり楽になります。
大まかな内容として
- Pythonを使ったランダムなダミーデータ一覧表の作成
- 一覧表からフォーマットに情報を転記する関数処理
- VlookUPを切り替えながらPDF保存までの自動化
3本でお届けします。
日報ダミーデータを作ろうと思った背景
本ブログで執筆中の連載記事「ズボラDX研究所」というテーマで
ノーコードツールだけ(極力)で作る日報解析のツールを作成中です。
【▼ズボラDX研究所】Dify×Makeで作る日報解析DXの奮闘はこちらから

その解析ツールで「日報をどれだけ一気に読みこませることが出来るのか?」という
AIやツールの限界を探る負荷テストとして、100枚一気に試してみようと閃いたのですが
100枚分の日報データをダミーで作るのも大変だな・・・。
ということで、ダミーデータ作成もズボラでやってしまおうという検証記事になっています。
- スプレッドシート
- Google Colab(オンライン上で出来るPythonの実行ソフト)
- AI(Pythonのコードを書かせる役割)
で完結する内容になっています。
「ちょうど、ダミーデータを作りたかったんだよね」
「PDFに一括で変換する方法知りたいんだよ」
というピンポイントな悩みをお持ちの方には参考になったりならなかったりする記事です。
日報ダミーデータのCSV作成の準備
まずはPDFにするための元データから準備していきます。
ダミーの製品リストと日報フォーマット
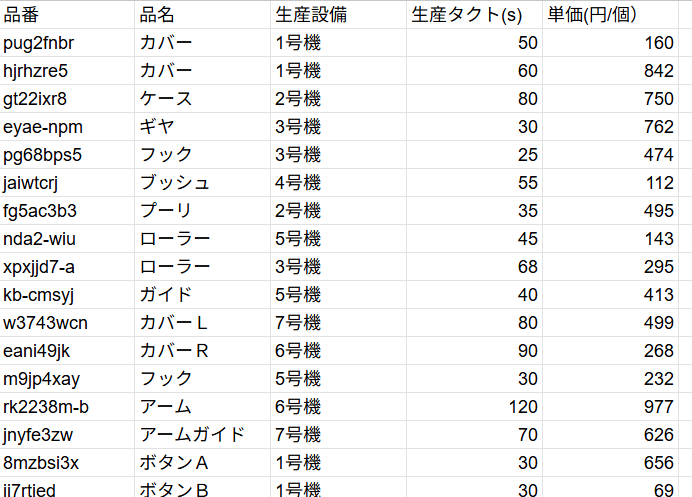
【ダミー品番リスト】
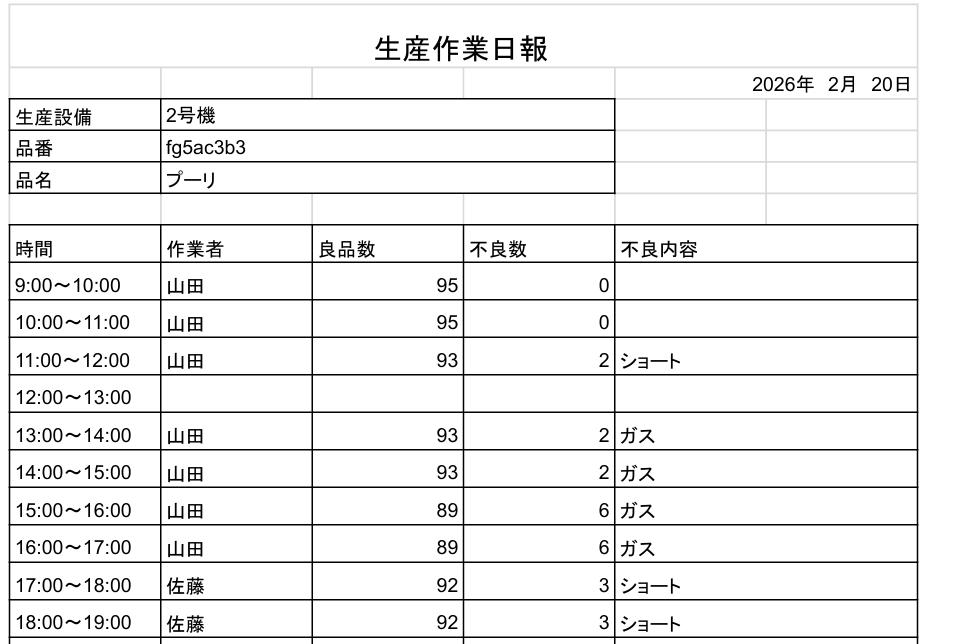
【日報フォーマット】
これは元々作っていたものを使用します。
ダミーの製品リストの品番は日本海商㈱システムツール【ランダムな文字列生成】を使用させていただきました。
日報データは以前手入力で作ったものを参考資料に使います。
これらを元に、100枚分(正確には98枚です。サバ読んでます)のデータを作成していきます。
AIでPythonコードを生成
100件分を作るのも面倒なので、AIにPythonコードを書いてもらいます。
【プロンプト名:製造現場のダミーデータ生成指示書】
タイトル:製造日報のシミュレーション用ダミーデータ作成(Python)
【目的】 製造現場のDX化のテスト用として、リアリティのある日報データ(CSV形式)を生成するPythonコードを書いてください。
【データ構成】
- 期間: 2026/03/01から14日間
- 設備: 1号機〜7号機の計7台
- 時間軸: 各設備、1日あたり9:00〜22:00まで1時間刻み(12:00〜13:00は休憩で除外)。
【必須条件】
- 製品マスタの紐付け: 添付の製品マスタを参照し、設備ごとに作る製品を固定してください。
- 日報の項目: 使用する日報は添付PDFです。フォーマットに記載の項目を理解してください。
- 生産能力(タクト)の反映: 製品ごとに1時間の生産数を変えてください(タクトが短いものは数は多く、長いものは少なく)。
- 作業者の交代: 17:00で日勤から夜勤へ作業者が交代するロジックを入れてください。
- 不良の発生: 全体の約10%の確率で「ショート」「バリ」などの不良が発生し、その時間は良品数が少し減るようにしてください。
【出力形式】
- Google Colabで実行して、即座にCSV(UTF-8-sig)をダウンロードできるコードにしてください。
- 列項目:日付, 設備, 品番, 品名, 時間, 作業者, 良品数, 不良数, 不良内容
このプロンプトを指示したら、数秒後に以下のPythonコードを書いてくれました。
コードはここをクリックしてください
import pandas as pd
import random
from datetime import datetime, timedelta
from google.colab import files
# 1. 製品リストの定義
products = [
{"id": "hjrhzre5", "name": "カバー", "mach": "1号機", "tact": 60},
{"id": "8mzbsi3x", "name": "ボタンA", "mach": "1号機", "tact": 30},
{"id": "gt22ixr8", "name": "ケース", "mach": "2号機", "tact": 80},
{"id": "fg5ac3b3", "name": "プーリ", "mach": "2号機", "tact": 35},
{"id": "eyae-npm", "name": "ギヤ", "mach": "3号機", "tact": 30},
{"id": "fnfhp7gb", "name": "ライトカバー", "mach": "3号機", "tact": 35},
{"id": "jaiwtcrj", "name": "ブッシュ", "mach": "4号機", "tact": 55},
{"id": "nda2-wiu", "name": "ローラー", "mach": "5号機", "tact": 45},
{"id": "kb-cmsyj", "name": "ガイド", "mach": "5号機", "tact": 40},
{"id": "rk2238m-b", "name": "アーム", "mach": "6号機", "tact": 120},
{"id": "eani49jk", "name": "カバーR", "mach": "6号機", "tact": 90},
{"id": "w3743wcn", "name": "カバーL", "mach": "7号機", "tact": 80},
{"id": "jnyfe3zw", "name": "アームガイド", "mach": "7号機", "tact": 70}
]
# 2. 基本設定
start_date = datetime(2026, 3, 1)
days = 14
machines = [f"{i}号機" for i in range(1, 8)]
time_slots = [f"{h}:00~{h+1}:00" for h in range(9, 12)] + [f"{h}:00~{h+1}:00" for h in range(13, 22)]
workers = ["田中", "山田", "佐藤", "鈴木", "高橋", "伊藤", "渡辺"]
defects_list = ["ショート", "フラッシュ", "キズ", "寸法不良", "成形不良"]
data = []
# 3. データ生成ロジック
for d in range(days):
curr_date = (start_date + timedelta(days=d)).strftime("%Y/%m/%d")
for mach in machines:
mach_prods = [p for p in products if p["mach"] == mach]
if not mach_prods: continue
prod = random.choice(mach_prods)
base_qty = int(3600 / prod["tact"])
for i, slot in enumerate(time_slots):
worker = workers[machines.index(mach)] if i < 7 else workers[(machines.index(mach) + 1) % len(workers)]
has_defect = random.random() < 0.1
def_qty = random.randint(1, 4) if has_defect else 0
def_type = random.choice(defects_list) if has_defect else ""
good_qty = base_qty - def_qty + random.randint(-2, 2)
data.append([curr_date, mach, prod["id"], prod["name"], slot, worker, good_qty, def_qty, def_type])
# 4. CSV出力と自動ダウンロード
filename = "dummy_reports_100.csv"
df = pd.DataFrame(data, columns=["日付", "設備", "品番", "品名", "時間", "作業者", "良品数", "不良数", "不良内容"])
df.to_csv(filename, index=False, encoding="utf-8-sig")
# 🚀 ブラウザからファイルをダウンロードさせる
files.download(filename)Pythonのコード見ると機械1台につき1~2品番しか抽出してないけれど
実験用のダミーデータだから、まぁよしとしよう。
Pythonを使って日報ダミーデータ(CSV)の作成
Google ColabでPythonコードを実行
先ほどのPythonコードをGoogle Colabで実行していきます。
Pythonを実行するにはVScodeやanaconda、最近だとDocker desktopといったツールを使うのが一般的ですが
環境構築に少し時間がかかります。
Google Colabはグーグルアカウントがあればすぐに使えるので
環境構築とか良く分からないよ!という方でも再現しやすいこちらを選択しました。
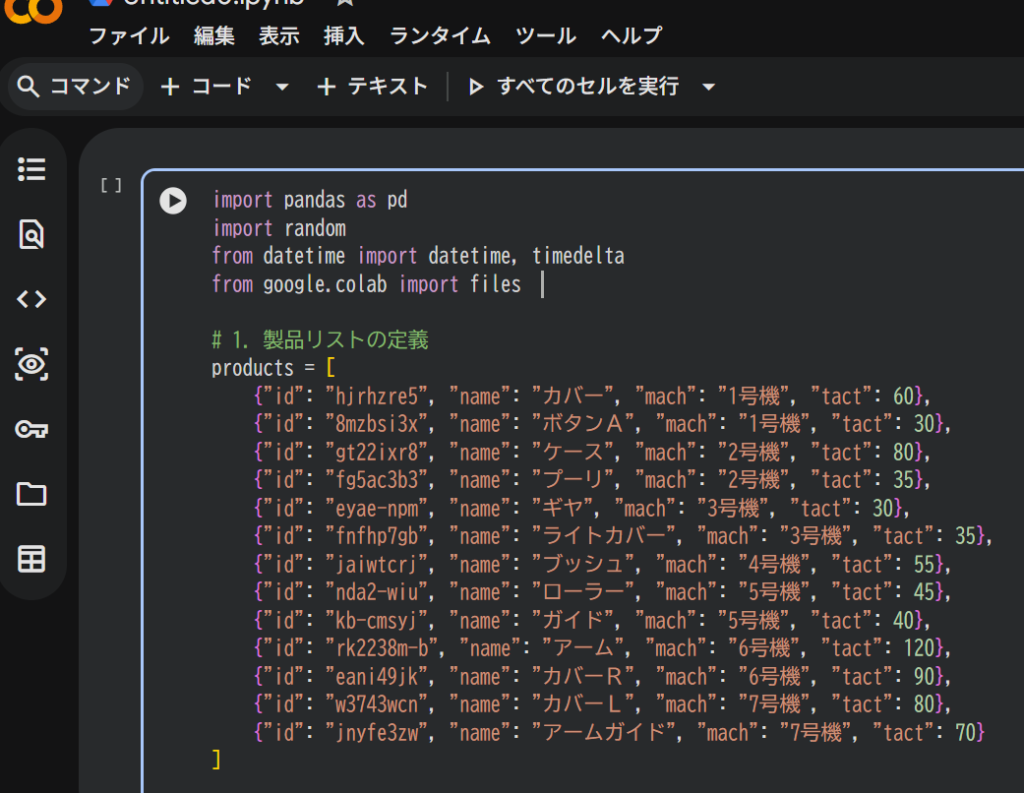
ここに先ほどのコードをGoogle Colabにコピペして、【▶】の実行ボタンを押します。
出来上がったダミーデータ(CSV)
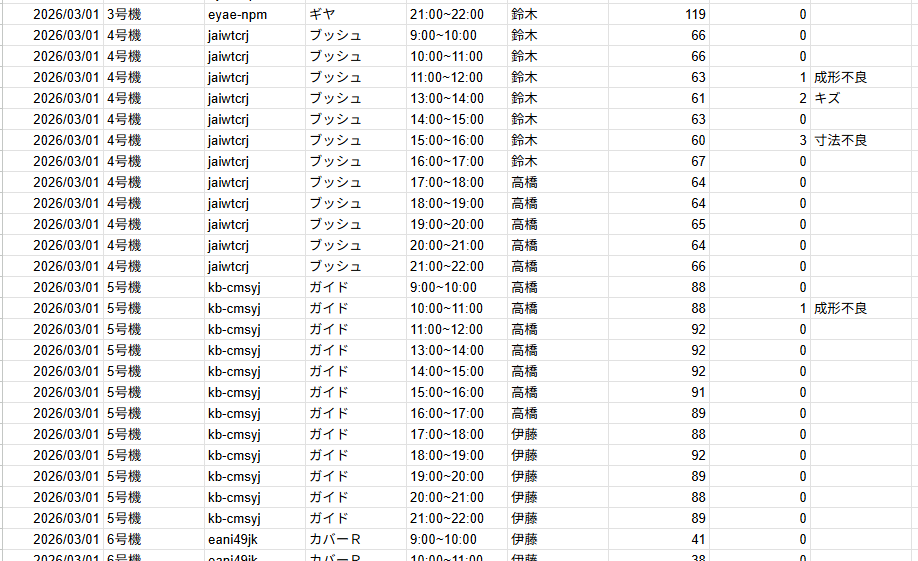
機械7台×12時間×14日分=1176行のダミーの日報データを一瞬で作成できました。
早すぎてコーヒーを飲む時間すらなく完成しました。
これで日報の元となるCSV情報作成は完了です。
関数を使って日報フォーマットへデータを転記する
今の日報データ(一覧表)だと、ズボラDX研究所でDifyでの実使用を想定した検証と違ってくるので
次は日報のフォーマットにデータを移していきます。
VlookUP関数の構築準備
とはいえ約100枚分のコピペなんて時間かかるので、スプレッドシートの関数を使って処理していきます。
Excelやスプレッドシートで表を作ったりしたことのある人はおなじみのVlookUP関数を使用します。
VlookUP関数で参照する数字をIF・AND関数で入力
今のまま単純に数字を打っていくと1~1176までの数字になって管理がめんどくさくなるので
この数字を98枚分の日報データ=1~98までで済むようにしていきます。
- 日付(現在のA列)の左側に新しく列を挿入
- 新しいA列(空欄)のA2セルから、VlookUPで引っ張るための数字を入れる
- 数字入力は関数 【=IF(AND(B2=B1, C2=C1), A1, A1+1)】を入力(A2セルに)
- A2セルをコピーして、その下のセル全部に貼り付けます。
この関数は簡単なIFとANDで作っていますが、内容を説明すると
- IF(もし)AND(B2とB1の内容が一緒、かつC2とC1の内容が一緒)
- これが合っていれば=A1のセルの数字を入力
- 間違っていたら(B2とB1、もしくはC1とC2 どれかが違っていたら)=A1の数字+1を入力
B列は日付、C列は設備なので、日にちか機械が切り替わったら数字を+1するという内容です。
この関数をA2(データの一番上の行)に入力して、一番下までコピペすれば完成です。
IFANDで追加したA列(一番左)が▼の画像です。
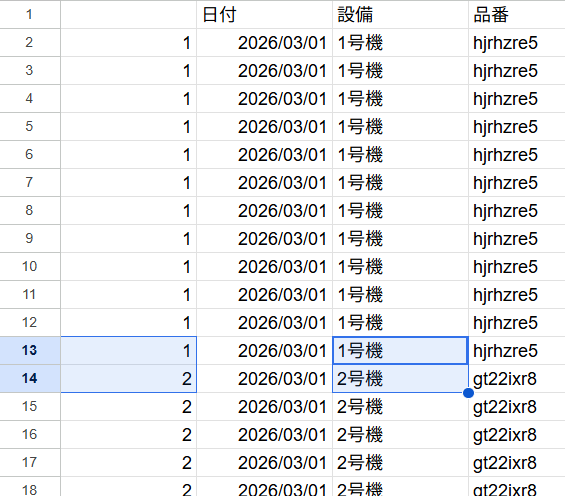
機械、もしくは日にちが変わったらVlookUPで検索するための数字(一番左の1➔2)も切り替わるようになります。
これでVlookUP関数を使うと、数字を切り替えるだけで簡単に
- 日付
- 生産設備
- 品番
- 品名
が切り替わる準備が出来ました。
表に名前を付ける
次はVlookUP関数の入力を簡素化するために、この表に名前を付けます。
①製品マスターのA1~J1177(表を全部)を選択します。
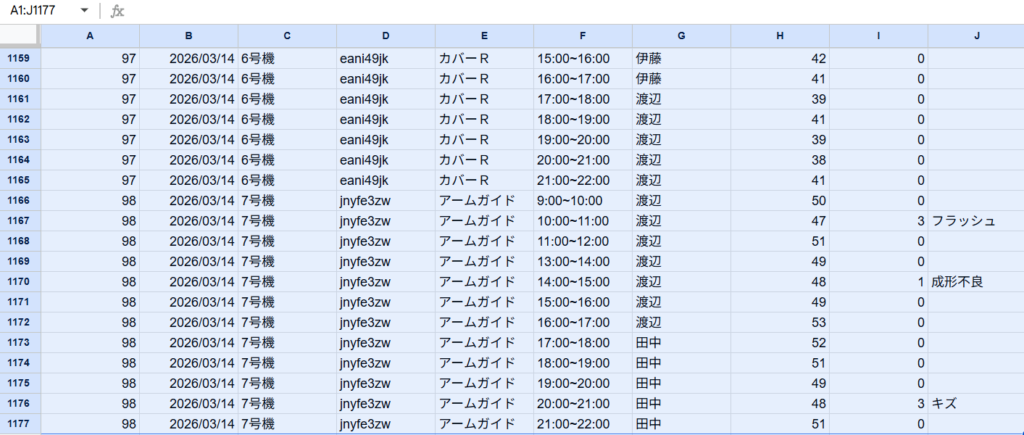
②左上(Aの上)にある名前ボックス(A1:J1177と書いてあるところ)をクリックして「data」と打ちます。
これで、VlookUP関数を入力するときに「data」と打つだけで、この表を参照することが出来るようになりました。
ちなみに今回は表を更新する予定がないのでA1~J1177までを範囲としましたが
下に新しい情報がどんどん増えていくって場合には、A列~J列全てを選択する方が無難です。
日報フォーマットにVlookUP関数を入力(スプレッドシート)
次に日報フォーマットにVlookUP関数を入れていきます。
①VlookUP関数で参照する数字を入れる用のセルを準備
このセルは任意のところで大丈夫ですが、PDFにしたときにこの数字を範囲に入れたくないので
今回はH4のセル(下の画像参照)にします。

H4のセル(1と入力しているところ)がさっき作ったマスターの表と連動しているイメージです。
このH4のセルには数字を入れるだけなので、関数とかは不要です。
②VlookUP関数で切り替えたいデータのところに関数を入れる
今回はVlookUP関数を使って、「生産設備、品番、品名、日付」の4つを
自動的に日報データ(一覧表)から引っ張ってきたいので
ここにVlookUP関数を入れています。
生産設備(B4セル):=vlookup(H$4,data,3,TRUE)
品番(B5セル):=vlookup(H$4,data,4,TRUE)
品名(B6セル):=vlookup(H$4,data,5,TRUE)
日付(F3セル):=vlookup(H$4,data,2,TRUE)
VlookUPは使える方も多いと思いますが
VlookUP(参照するセル(先ほどのH4セルをここでは選択),data(リスト),数字(左から何番目を持ってくるか,TRUE(一致))
H4(先ほど1と書いてあったところ)の数字を2、3と切り替えるだけで、表の中身が更新されていきます。

- 5に変えたら5号機のデータに

- 10に変えたら、次の日の3号機のデータに
これで日付、生産設備、品番、品名の4つの項目が、数字を変えるだけで一瞬で切り替わるようになりました。
日報データから作業実績を引っ張る
次は日報の下の方、時間ごとのデータを引っ張ってきます。
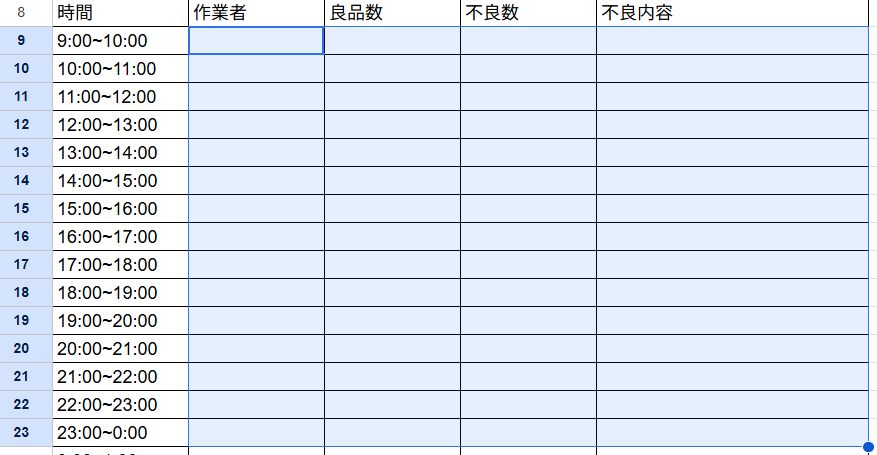
上のスクショの青枠の部分を、先ほどの製品リスト(data)から一瞬で持ってきます。
ここのコツは
- 日付
- 生産設備
- 時間
この三つ全てが一致する条件のdataの行から、データを持ってくることです。
フィルター関数で作業実績を一瞬で転記する
B9セル(上の図の選択しているところ) 9:00~10:00の作業者のところに以下の関数を入れます。
=IFERROR(FILTER(dummy_reports_100!$G:$J, dummy_reports_100!$B:$B=$F$3, dummy_reports_100!$C:$C=$B$4, SUBSTITUTE($A9, “~”, “~”)=dummy_reports_100!$F:$F), “”)
ちょっと難易度上がって、長文の関数になりましたね・・・。
1. FILTER関数は文字通り「フィルター」の役割
「データ(dummy_reports_100)」のシート中に、約1,200行のデータが混ざっています。
そこから、日付・設備・時間という3つのフィルターを使って、今必要な「1行」だけをすくい上げています。
2. 3つの条件の例
- 第1の鍵(日付): 「2026/03/01のデータだけにして!」
- 第2の鍵(設備): 「その中から、1号機のものだけにして!」
- 第3の鍵(時間): 「さらに、9:00〜10:00のものだけにして!」
この3つがガチッと合ったとき、初めてデータが日報の枠の中に転記されます。
この例だと、【2026/03/01の1号機の9:00~10:00】のデータを表から探して転記するイメージです。
なので、先ほどのVlookUP関数で日付や機械を変更するだけで、作業実績もその行に合わせた内容に更新されます。
引っ張ってくる範囲もdummy_reports_100のデータのG列~J列の4列を選択しているので
一番左の作業者のところに関数を入れたら、そのまま4列分(良品~不良内容まで)データが入っていきます。
めちゃくちゃ便利。
3. SUBSTITUTEとIFERRORは気遣いみたいなもの
IFERROR: もしデータがなくても、画面にエラー(#N/A)を出さずに「そっと空白にしておく」という処理。
SUBSTITUTE: 「〜」と「~」全角、半角の書き間違いを勝手に直してくれる「自動修正機能」。
フィルター関数を実際に入力
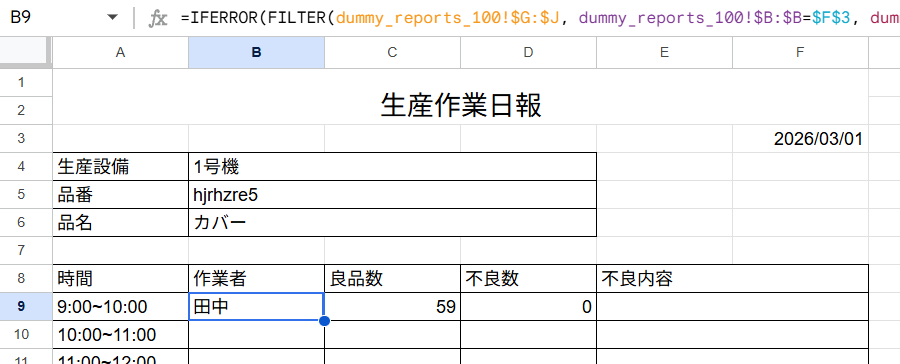
B9セルに先ほどの関数を入れると、作業者だけじゃなく一瞬で「作業者」「良品数」「不良数」が出てきました。
不良内容のところは、データが空白(不良0)なので、IFERROR関数で何も表示されない状態です。
あとはこの数式をズラーっと下にコピペしていくだけです。
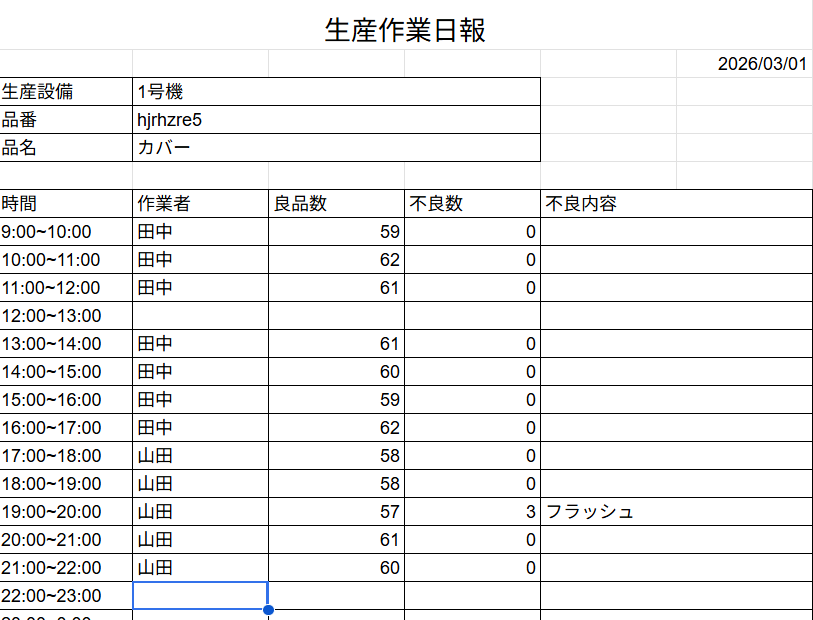
これでAIに作成させたダミーの日報リストと、作業日報のフォーマットが完全に連動しました。
あとはVlookUP関数で、H4のセル(1と入ってたところ)の数字を2,3と切り替えるだけで
勝手に日報のフォーマットが切り替わっていきます。
これで日報フォーマットをPDF化するための準備が終わりました。
この日報を1枚ずつPDFへ変換
後はDifyで読み込ませるために、7機×14日分=98枚のPDFに変換するだけ。
H2のセルを順番に変えていきながら、手作業でPDF保存でもいいのですが
量が多いのでここでもズボラしようと思います。
【結論】一回失敗しました!(この後やり方変えて成功してます)
98枚一括PDF処理は出来ませんでした・・・!
一応ここにやったことはまとめておきます。
①拡張機能のAPPs Scriptを使用
スプレッドシートの上にある拡張機能から【Apps Script】を選択
開くと▼こんな画面が出ます。
ここに以下のコードを打ちこみます。
コードの内容はここをクリック
function generateAllPDFs() {
const ss = SpreadsheetApp.getActiveSpreadsheet();
const sheet = ss.getSheetByName("シート1"); // ★シート名が違う場合は書き換えてください
const folder = DriveApp.createFolder("日報PDF一括出力_" + new Date().toLocaleDateString());
const ssId = ss.getId();
const sheetId = sheet.getSheetId();
for (let i = 1; i <= 98; i++) {
sheet.getRange("H4").setValue(i);
// 1. 強制的に計算を完結させる(念押し)
SpreadsheetApp.flush();
// 2. 休憩時間を少し長め(2.5秒〜3秒)にする
// データが飛び飛びになる場合は、ここを 長くしてみてください
Utilities.sleep(2500);
// ★ここで「日報の枠(例:A1からF35)」を指定します
const rangeParam = "&range=A1:F35";
const url = "https://docs.google.com/spreadsheets/d/" + ssId + "/export?exportFormat=pdf&gid=" + sheetId + rangeParam;
const token = ScriptApp.getOAuthToken();
const response = UrlFetchApp.fetch(url, {
headers: { 'Authorization': 'Bearer ' + token },
muteHttpExceptions: true // ★エラーで止まらずに内容を確認できるようにする
});
if (response.getResponseCode() == 200) {
const blob = response.getBlob().setName("日報_管理番号" + i + ".pdf");
folder.createFile(blob);
} else {
console.log("番号 " + i + " でエラーが発生しました。少し時間を置いて再開してください。");
}
}
Browser.msgBox("指定範囲でPDFを出力しました!");
}コードのポイントは
- Googleのサーバーに負担をかけないよう2.5秒休憩
Utilities.sleep(2500);
これを設定しないと、サーバーに一瞬で98枚のデータを連打で送ることになって
「リクエストが多すぎ!!攻撃か!?」とエラー:429が出るので
間隔をあけながら処理していきます。 - 強制的に計算を完結させる(念押し)
SpreadsheetApp.flush();
スプレッドシートのVlookUPの切り替えとPDF保存にタイムラグがあると
データが飛ぶ恐れがあるので、計算完結したタイミングで保存するように処理。
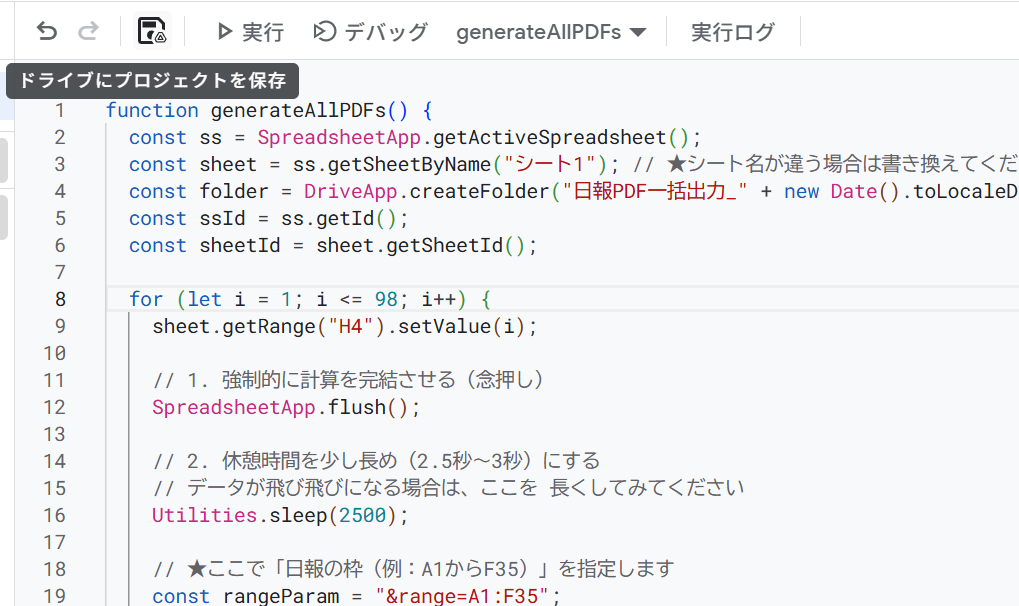
上の図のように、Apps Scriptにコードを打ちこんだら【保存】を押します。
スプレッドシート(日報フォーマット)にコマンド実行のボタンを追加
挿入➔図形描写で適当なボタンを作ります。
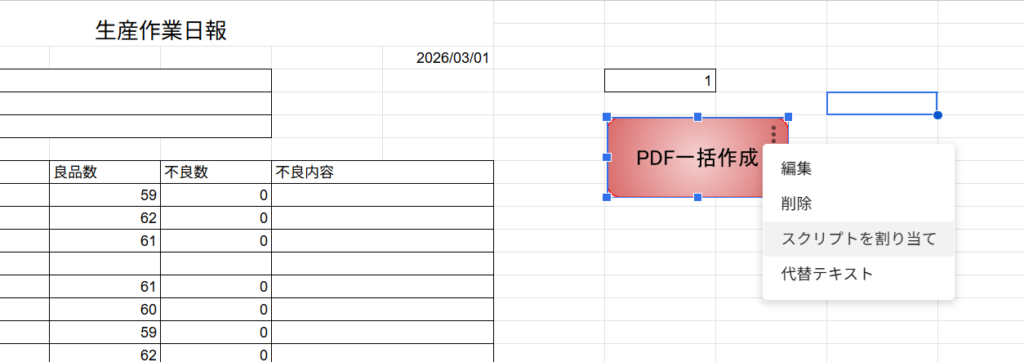
作ったボタンの右上の3点リーダーをクリック➔スクリプトを割り当てを選択します。
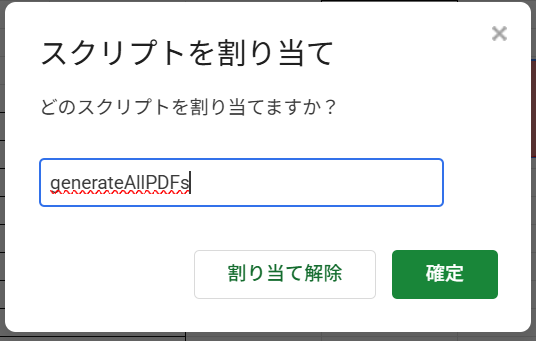
上の図のように「generateAllPDFs」を入力します。
この名前は先ほど紹介したコードの一番上の行で、スクリプトの名前を付けたので
その名前をつかってください。
これでこのボタンをクリックすると、先ほどのPDF一括作成が出来るようになりました。
スクリプトを実行してみます。
ボタンを押すと認証が必要です。と出るのでOKを押します。
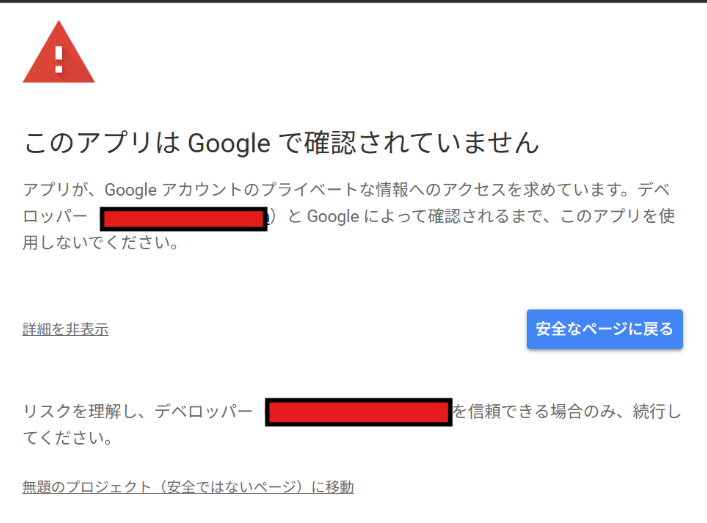
このように表示されますが、自分で組んだプログラムなので
左下の無題のプロジェクトに移動をクリックします。
再度ボタンを押すと上の画像のように、「スクリプトを実行しています」と表示されます。
順番にH4セルの数字が切り替わっていきます。
段々と日報PDFがたまっていきます。
その間に私はコーヒーを飲みます。
コーヒーを飲んでヤマトから荷物を受け取ってる間に完了してました。
Google driveに保存されたPDFを確認
どれどれ・・・
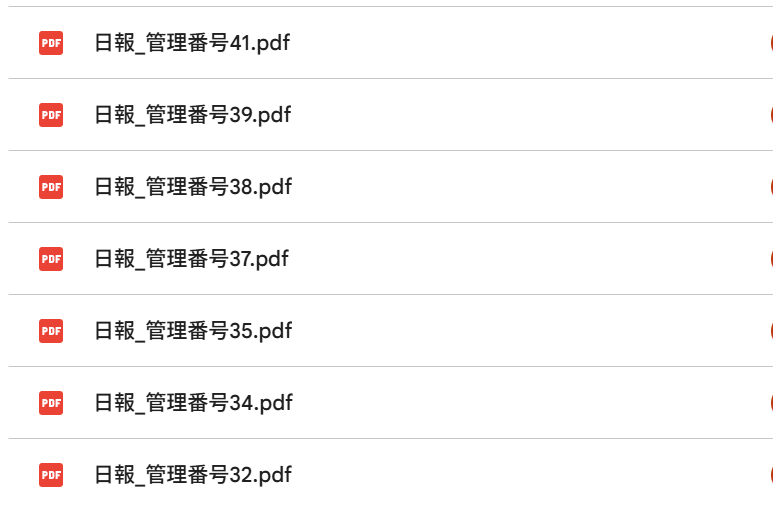
出来・・・てない・・・。
データが飛んでますね。待機時間2.5秒じゃ短かったかな?
先ほどのUtilities.sleep(2500)を5000に変更
待機時間が短くて、PDF化が追い付いていないのかなと想定して
待機時間を伸ばして再度実行します。

ダメでした。
待機5秒+PDF2秒として1枚出力で約7秒と仮定して
7秒×98枚=686秒かかる計算ですが
APPs Scriptは6分(360秒)でタイムアウトになるみたいです。
予想ですが、最初の方は連続で出来てて20枚を超えると飛び飛びになってきていたので
サーバー側の負荷がたまって、PDF保存が追い付かないのかなと思ってます。
実際一括PDFにする場合の目安としては10~20枚くらいが限界っぽいです。
なので98枚PDF一括生成は無理っぽいので10枚ずつくらいに分割にします。
まぁ、どうせAIに読み込ませる用でフォントも変えながら出力したかったし?
ここから本番~区切りながら自動PDF化~
気を取り直して、再度チャレンジしていきます。
開始番号と終了番号の設定
元のスクリプトはH4のセル(VlookUP参照の数字)を【1~98】まで順番に実行としていたので
これを
- 1~10
- 11~20
- 21~30・・・
と変えながらPDFにする必要があります。
ただ出力する度にApps Scriptを開いてコード書き換えるのも面倒なので
スプレッドシートに開始番号と終了番号を入力する欄を設けました。

この開始番号と終了番号に数字を入れれば、その間の分だけがPDFで保存されていきます。
Apps Scriptを開始番号・終了番号を参照するように変更
先ほどのコードで1~98まで実行としていたところを
【開始セル(H5)の数字~終了セル(H6)の数字】までに変更します。
コードはこちらをクリックしてください。
function generateAllPDFs() {
const ss = SpreadsheetApp.getActiveSpreadsheet();
const sheet = ss.getSheetByName("シート1"); // ★シート名が違う場合は書き換えてください
const folder = DriveApp.createFolder("日報PDF一括出力_" + new Date().toLocaleDateString());
const ssId = ss.getId();
const sheetId = sheet.getSheetId();
// ★追加:セルから開始と終了の数値を取得する
const startNum = sheet.getRange("H5").getValue(); // H5に開始番号
const endNum = sheet.getRange("H6").getValue(); // H6に終了番号
// 念のため、変な文字が入っていないかチェック(数値じゃなければ中止)
if (isNaN(startNum) || isNaN(endNum)) {
Browser.msgBox("H5とH6には数値を入力してください");
return;
}
for (let i = startNum; i <= endNum; i++) {
sheet.getRange("H4").setValue(i);
// 1. 強制的に計算を完結させる(念押し)
SpreadsheetApp.flush();
// 2. 休憩時間を少し長め(3.5秒)にする
// データが飛び飛びになる場合は、ここを 長くしてみてください
Utilities.sleep(3500);
// ★ここで「日報の枠(例:A1からF35)」を指定します
const rangeParam = "&range=A1:F35";
const url = "https://docs.google.com/spreadsheets/d/" + ssId + "/export?exportFormat=pdf&gid=" + sheetId + rangeParam;
const token = ScriptApp.getOAuthToken();
const response = UrlFetchApp.fetch(url, {
headers: { 'Authorization': 'Bearer ' + token },
muteHttpExceptions: true // ★エラーで止まらずに内容を確認できるようにする
});
if (response.getResponseCode() == 200) {
const blob = response.getBlob().setName("日報_管理番号" + i + ".pdf");
folder.createFile(blob);
} else {
console.log("番号 " + i + " でエラーが発生しました。少し時間を置いて再開してください。");
}
}
Browser.msgBox(startNum + "番から" + endNum + "番までPDFを出力しました!");
}追加した内容を要約すると
- H5のセルに【startNum】という名前を与える
- H6のセルに【endNum】という名前を与える
- PDFを保存➔次のページ切り替え➔PDF保存を
【startNum】の数字から【endNum】の数字まで実行
こういうプロセスに変更しました。
テストで実行してみます
とりあえず1~10まで指定して10枚PDF出力してみます。
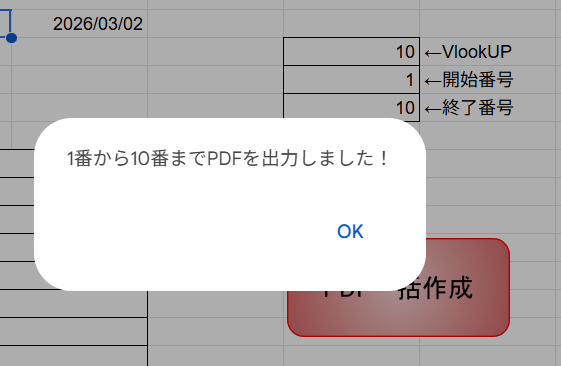
ちゃんとフォルダを見に行っても出力されてました。
これで、任意の量を一括でPDF化する仕組みは出来ました。
AI読み取り実験用にフォントを変えながらPDF出力
今回の目的は「AIが手書きでもちゃんと判断できるかどうか」なので
AIの読み取りテスト用にフォントを変えながらPDFを生成していきます。
今回使うフォントを紹介

まぁ、人が読むにしても読みにくいフォントも混ぜていきます。
そうこうしている内にPDF98枚の生成が完了しました。
途中ご飯を挟んだりしたので時間が空いているところもありますが
- 10枚ずつ生成
- フォントを全部変更しながら
でも、10枚生成するのに大体1~2分くらいで終わります。
生成している間にブログ記事を書き進めたりしようとしても
1~2行書いている間に生成が終わりました。
まとめ
ダミーデータ100枚(98枚ですが)を手書きやExcel手入力で作ろうとするって考えると
憂鬱になるような作業ですが
この方法であればコーヒー飲みながら片手間に出来てしまいます。
これがDXです(?)
この記事を読んだあなたも
「あ、ダミーデータ作りたいな」
って思ったらこの方法を真似してみてください。
【連載】ズボラDX研究所でもノーコードツールで作る日報解析システムを試行錯誤してますので
こちらからぜひご覧ください。







