

「AIなら100枚くらい一瞬で読んでくれるでしょ!」
そんな軽い気持ちで始めた日報100枚ノック。
しかし、Difyはそもそも10枚すらアップロードできませんでした。
今回は、Difyを使ったOCR解析のガチ検証・第2弾です。
標準フォントから少しクセのあるデザインフォントまで、全10種類・計98枚の日報をAIに処理させるプランです。
最終的に今回の検証で解読率99.44%を叩き出したAI。
フォント毎の読み取り精度の比較やOCR解析を導入する上で気を付けたいワークフローを解説しています。
【Dify×Makeでつくる】日報解析ツールの制作過程・検証記録は
▼こちらの記事にまとめています。

1. OCR解析結果・フォント別の読み取り精度発表
検証途中が長いので、最初に解析結果を発表します。
①項目別の解析結果
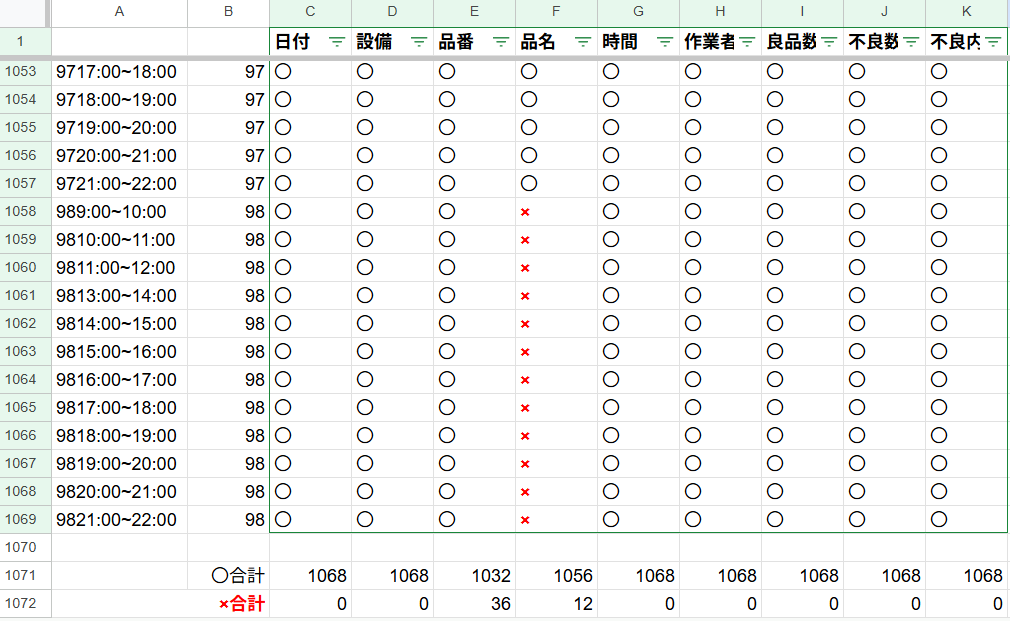
一番下に、〇と×の累計数字を記載しています。
品番間違い:36件/1068件 約3.37%
品名間違い:12件/1068件 約1.12%
他の時間や日付、作業者、数字などは間違いゼロ件でした。
②フォント別解析結果
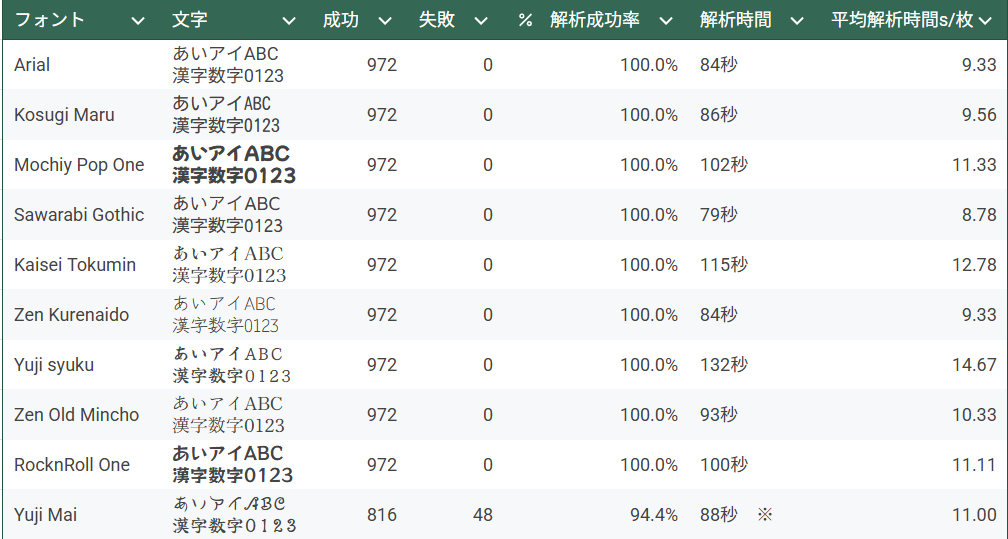
※Yuji Maiは9枚ではなく8枚の解析結果です(9枚作ってなかったので・・・)
今回試した中では、読み取り難しそうと思っていた「Yuji Mai」のフォントのみが
OCR読み間違いを起こしていました。
解析時間はYuji Syukuフォントが一番長いですが、解析間違いは起こしていないです。
③間違えたところ


- 日報No91:wcnの文字をギリシャ語と勘違い。似たような文字でギリシャ語の単語があるから?
- 日報No94:nをキリル文字?に誤読。確かに似ているけれども・・・。
- 日報No95:小文字のcとoを読み間違い。
- 日報No98:「ガ」を「ケ」と読み間違い。
ここから先は検証にあたってのプロセスと
OCR解析を導入するにあたって、意識しておくべき考え方をまとめています。
2. 【悲報】Difyの限界。100枚一括投入は「始まりすらしない」
今回の検証ではフォント別に処理を区切って、10枚ずつ読みこませてみます!
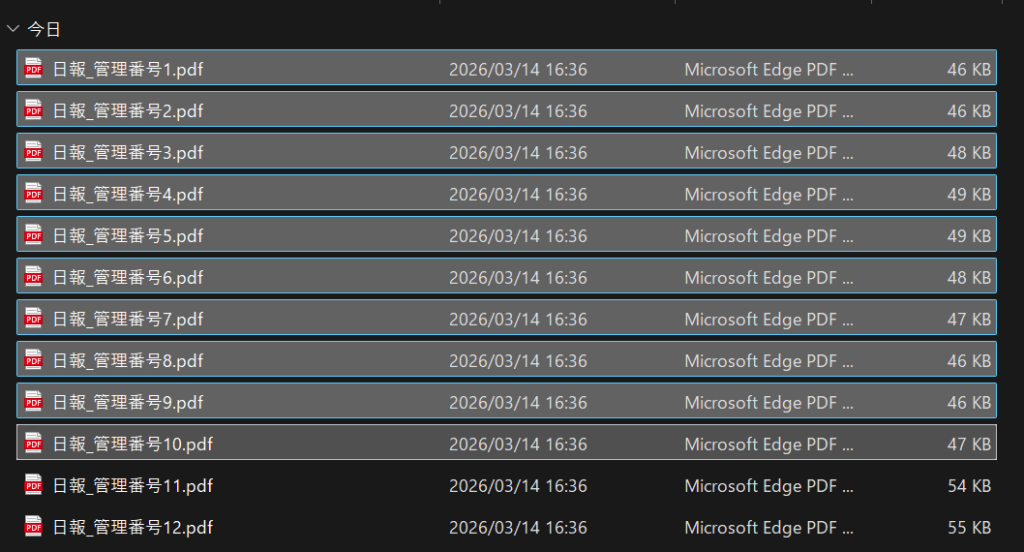
と、ここで問題が・・・。
10枚選択してもアップロードは9枚までしかされていません。
何度試しても、どれだけマウスをカチカチしても、10枚目はグレーアウト。
どうやらDifyの現在の仕様では、一度にアップロードできるファイルは9枚が限界のようです。
「100枚ノック」という威勢のいいタイトルが、開始5秒で崩れ去りました。
しかし、ここで諦めるわけにはいきません。
検証プランを以下のように「現実的な路線」へシフトします。
- 当初の計画: 10フォント × 10枚 = 100枚のガチ検証
- 修正後の計画: 各フォント9枚ずつ(※Yuji Maiのみ素材の関係で8枚) = 合計89枚ノックへ!
100枚には届きませんでしたが、89枚でもOCRの精度を測るには十分すぎるボリュームです。
気を取り直して、この「89枚の日報データ」をAIにぶつけていきます!
2. 試運転:プロンプトとトップKの微調整
まずは標準フォント「Arial」で試運転してみます。
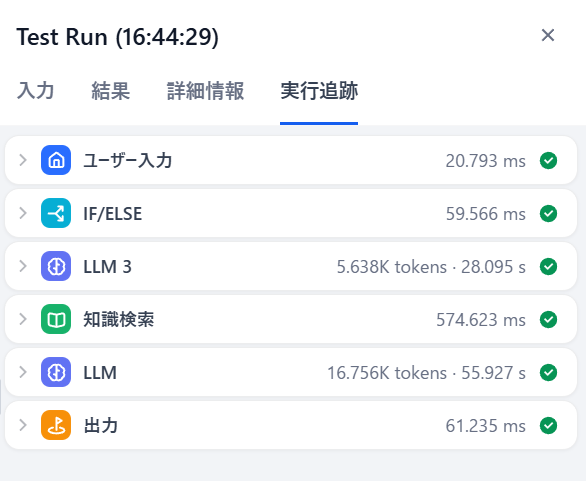
LLM(AI)が考えているところ以外はめちゃ早い(単位がミリ秒)ので
実質LLMの解析時間=作業時間と思っても大丈夫そうです。
Arialは約84秒で解析完了しました。
「作業時間」が「標準タクト」にすり替わっている
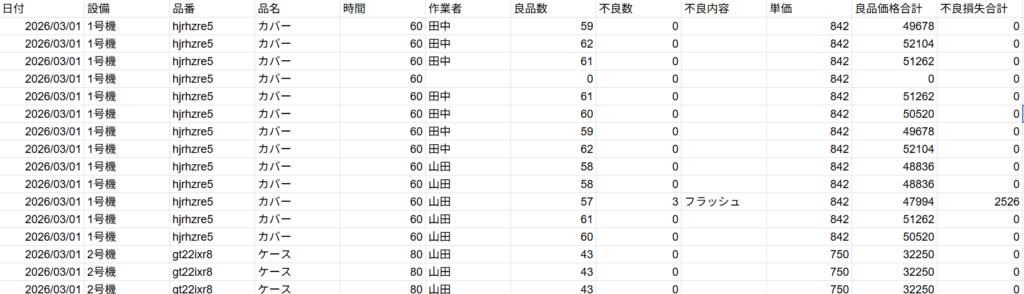
出力されたデータを見てみると、【時間】の列が製品マスタの標準タクトを引っ張ってきている。
ここは日報に記載の作業時間(9:00~10:00/10:00~11:00など)を引っ張ってきてほしいので
AI解析のプロンプトを微修正し、ナレッジではなく日報の時間を引っ張ってくるように指示しなおします。
品番が5個で止まる……「トップK」設定の変更
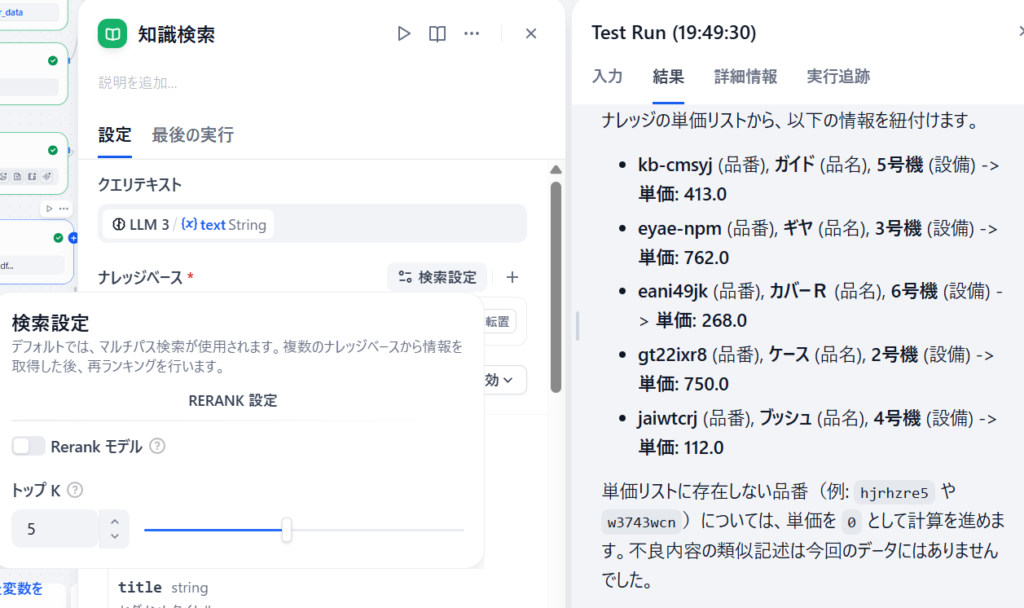
解析結果(右側AI解答欄)を見てみると

単価リストに存在しない品番
(例 hjrhzre5やw3743wcn)
については単価を0として計算を進めます。
とのことで、ナレッジ(製品リスト)が5個しか読み取りできていませんでした。
ナレッジのトップKを10まで引き上げて再度実行してみます。
検証1回目:標準フォント「Arial」での設定完了
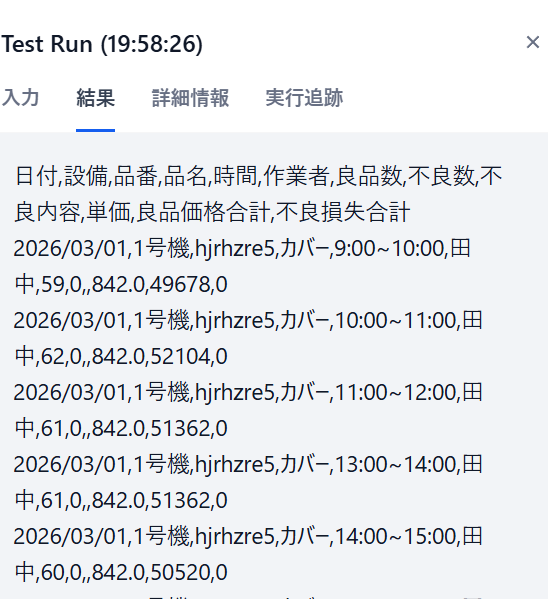

“日付,設備,品番,品名,時間,作業者,良品数,不良数,不良内容,単価,良品価格合計,不良損失合計\n2026/03/01,1号機,hjrhzre5,カバー,9:00~10:00,田中,59,0,,842.0,49678,0・・・・
これでちゃんと日報解析は出来たので、フォント別OCR解析をスタートしていきます。
3. フォント別・OCR解析マラソンスタート!

上記フォント+スプレッドシート標準のArialの計10種類で検証します!
癖の強い手書きフォントから、細字、太字まで様々なものをピックアップしてみました。
このフォントで、AIが読み取れるのか実力評価していきます!
OCR解析の検証・評価内容
今回のフォント別検証では下記の項目を評価したいと思います。
- フォント別読み取り精度
- フォント別の解析時間
- 間違い箇所の整理と傾向
解析結果が出たら、これらを整理して次の実験に活かしていきたいと思います。
解析完了➔元データとの照合へ
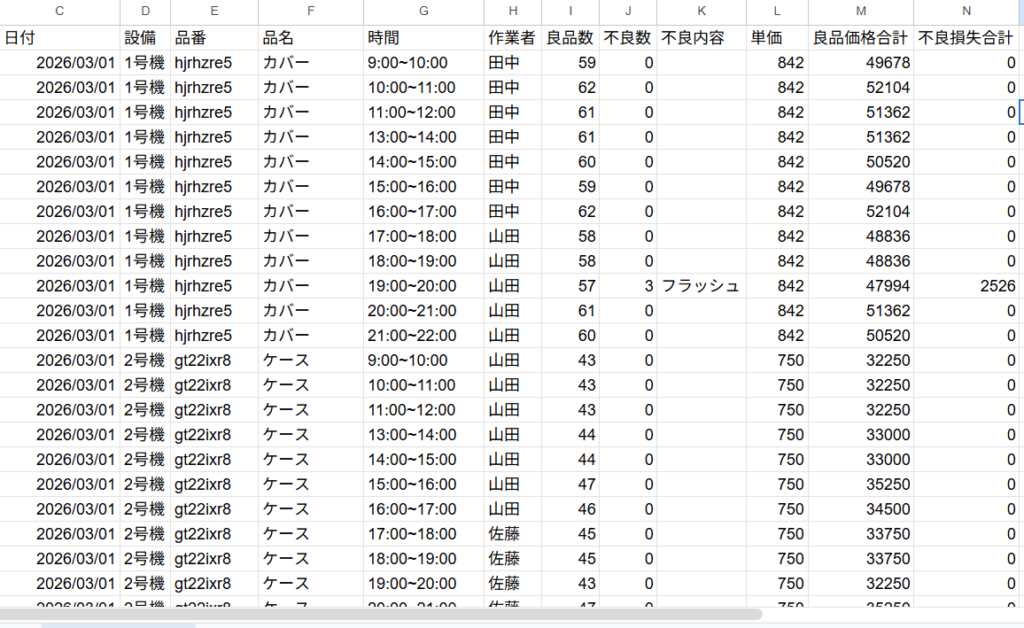
Difyに日報を解析させて出力したデータがこちら
ナレッジの単価も引っ張って、良品と不良の合計金額も計算済みです。
あとはこのデータが、元のデータとの違いがどれだけあるかを比較していきます。
4. 1000行超えのデータをVLOOKUPで照合する方法
この比較を1行ずつ目で見てっていうのは、正直無理なので
IFとVlookupを使って、データの相違を確かめていきます。
①元のデータと、今回OCR解析したデータを一つのスプレッドシートにまとめる
比較しやすいように一つのスプレッドシートに両方のシートをコピーします。
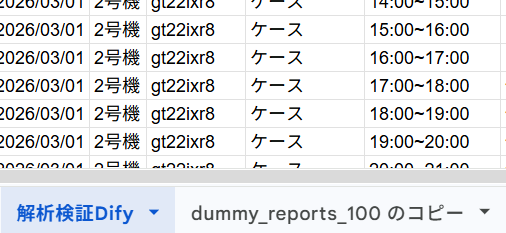
②DifyでOCR解析したデータにVlookup参照用の数字を挿入
これは番外編でもやったIFAND関数を使いますが
今回は日報を9枚ずつしかできなかったため10、20などの日報を飛ばしています。
元データとズレが無いように、10や20を飛ばしてナンバリングしていきます。

一番左の列がVlookup参照の数字ですが、9の次は11になるようにしています(10番は解析していないため)
同じように20、30、40・・・も飛ばしていくような関数にしています。
=IF(ROW()=2, 1, IF(AND(C2=C1, D2=D1), B1, IF(MOD(B1+1, 10)=0, B1+2, B1+1)))
関数でやっていることを少しだけ説明すると
- IF(もし)このセルが2行目(ROW)なら1を入力
- ➔違う場合:C2とC1が同じ且つD2とD1が同じ場合はB1の数字を入力
- ➔C/Dのセルが違う場合:B1の数字+1した数字を10で割ったときに余りが0(割り切れるかどうか)
- ➔割り切れる場合:B1の数字+2をしてね
- ➔割り切れない場合:B1の数字+1をしてね
という、IF(条件分岐)を使いまくった式になっています。
これを一番下までコピペすると、10、20、30といったキリのいい数字を飛ばしてナンバリング完了します。
③VLOOKUP用のユニークキー作成法
今②でVlookUpの数字をやったじゃん。と思うかもしれませんが
数字1つにつき、一番上の1行しか引っ張れないのがVlookUp関数です。
このままだと同じ数字があって一番上の行しか参照できないので
1行につき1種類の被らないコードにしなくてはなりません。
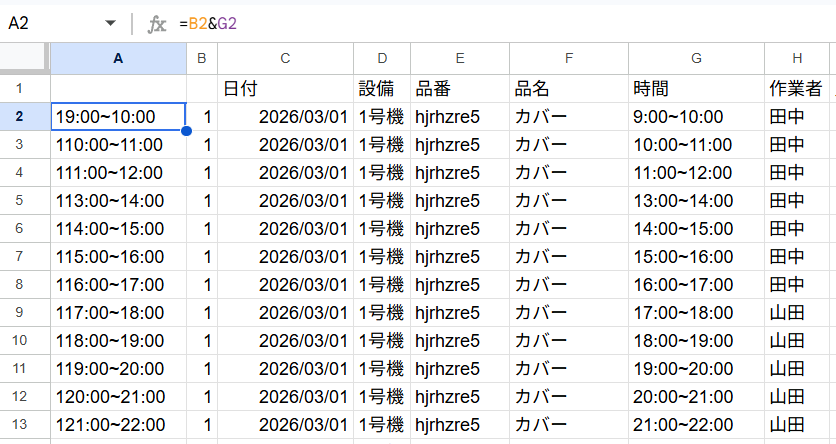
A列を新しく挿入して、=B2(Vlookupの数字)&G2(作業時間)を入れます。
こうすると、Vlookupの1+9:00~10:00 という文字を合体して、19:00~10:00という文字列が出来ます。
19:00~10:00って・・・超ブラックですね。
何はともあれ、これで全ての行に違った文字(キー)が出来ました。
同じことを元データにも行うことで、Vlookupで指定したら二つのシートを参照する準備が出来ました。
IFとVLOOKUPを組み合わせた「自動○×判定」
Difyが解析したデータ、元データともう一つ比較用のシートを追加します。

比較用にシートにも、元データと同じヘッダー行を作り
A列にはVlookup参照するために先ほど作ったユニークキー文字列(VlookUp+時間)を入れます。
コピー➔文字列の貼り付けで完了です。
完成した表がこちら
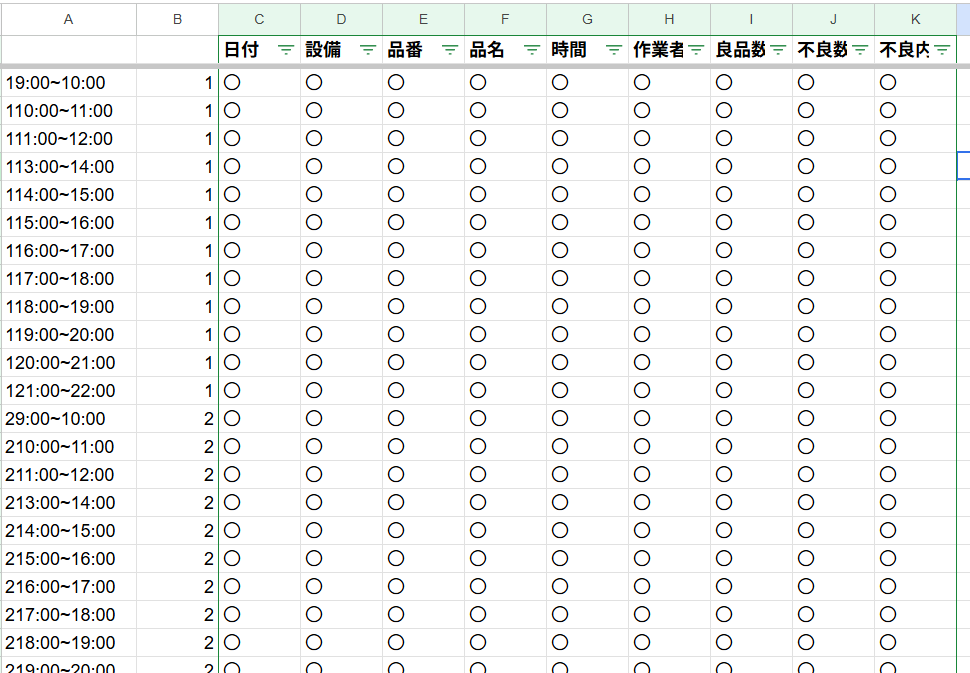
〇、×が入っているところには関数を入れています。
=if(Vlookup($A2,data,3,false)=vlookup($A2,dify,3,false),”〇”,”×”)
IFとVlookUpの組み合わせです。
数式の中の「data」は元データ、「dify」は解析したデータの表を名前を付けてます。
この関数でやっている処理は
元データと解析データの入力内容が同じだったら〇を
間違っていたら×を出力
というシンプルな内容です。
〇になっている箇所は、Difyの解析が元データと同じ(正しく読みこめているところ)
×になっている箇所は、解析が間違っているところです。
これで1000行越え、項目9個=9000カ所以上の比較が完了し
冒頭①の解析結果が作成となりました。
6. 考察:OCR解析とどう付き合っていくか
今回のガチ検証で見えてきたのは、AIの「得意・不得意」がハッキリしていることです。
- 太字・細字: 意外と精度に影響なし。
- クセ強フォント: 文字が独立していれば、デザインが派手でも余裕。
- 最大の敵: 「字と字の繋がり」。筆記体のように繋がると、一気に誤読が増えます。
「たまに間違えるなら使い物にならない」と切り捨てるのは簡単です。
でも、大切なのは「AIは間違えるもの」という前提でワークフローを組むことではないでしょうか。
- 膨大な情報の90%はAIに丸投げして、爆速で処理させる。
- AIが「自信がない」部分だけ、人間がサッと確認する。
- 人間のフィードバックを糧に、さらに精度を上げる。
100%丸投げではなく、AIを「優秀だけどたまにドジな新人」として扱う。
このチェック体制さえ作れば、転記ミスや計算ミスといった「人間のケアレスミス」を撲滅しつつ
圧倒的な時短が実現できるはずです。
まとめ
今回、残念ながらDifyの仕様制限により「100枚一括処理」という野望は潰えましたが、そのおかげで非常に価値のあるデータが取れました。
検証の結果、叩き出した解読率は99.44%
「Yuji Mai」のような超個性派フォントを除けば、100%の精度で日報を読み解けることが証明されました。
今回の検証を通して、私が一番伝えたいことは
「AIに100点満点を求めて、導入を諦めるのはもったいない」ということ。
人間だって、寝不足の日は文字を書き間違えますし、計算ミスもします。
大事なのは、AIに全責任を負わせるのではなく、
「AIが9割の重労働をこなし、残りの1割を人間が最終チェックする」という役割分担。
これこそが、現在の業務フローを劇的に進化させる「正解」ではないでしょうか。
今回の課題だった「Yuji Mai(崩し文字)」の克服や、アップロード制限の回避策など、
まだまだ深掘りできる要素はたくさんあります。
次回は、この「99.44%」をさらに「100%」へ近づけるためのプロンプト改良や、
さらなる自動化の繋ぎ込みに挑戦したいと思います!







