

「ようやく予算を通して導入したSaaS(生産管理や在庫管理システム)。でも、いざ動かそうとしたら、数万件の部品データや仕入先リストが空っぽで、立ち止まってしまった……」
製造業のDX担当者にとって、最大の障壁はシステム選びではありません。
その手前にある「マスタ整備」というデータ入力作業です。
現場から集まってきたExcelは
- 全角・半角がバラバラ
- 型番が古い
- そもそも空欄だらけ
こんなことも、珍しくはありません。
これを手作業で直していたら、システムが稼働する前にあなたの心が折れてしまいます。
今回は、この「マスタ整備地獄」を、PythonとAIワークフロー(Dify)を使って
最短3日で突破する方法を紹介します。
なぜ「マスタ整備」でDXは止まるのか?
製造業の現場において、マスタ整備が「地獄」と化すのには理由があります。
属人管理されたExcel
- 「ボルトM6」や「M6ボルト」などの表記ゆれ
- 品番が変わっているのに管理表は古い品番のまま
拠点ごとに管理方法が異なり、情報が統一されていない。
情報の分散
- 「価格は購買のExcel」
- 「図面番号は設計のPDF」
- 「在庫場所は現場の紙」
と、情報がバラバラで、一つに統合するだけで日が暮れる。
「データ」ではなく「メモ」
- セルの中に「※現在は使用禁止」といった備考欄
- セルの色塗りで状態を判別している
データとは呼べない状況で、そのままではシステムに取り込めない。
この状態を前にして、現場に「正しい情報を入れてください」と頼んでも、
「忙しいのに余計な仕事を増やすな」と反発されるのが関の山です。
DX担当者は、ここをテクノロジーでスマートに解決して見せる必要があります。
【解決策①】Pythonで「データの整理」を一瞬で終わらせる
データは揃っているけれど、システムが受け付けない形式になっている。
そんな「データの加工・整形」にはPythonが最適です。
ITに詳しくなくても、「pandas(パンダス)」というライブラリ(便利な道具セット)の名前だけは覚えておいてください。
Pythonで具体的にやること
複数ファイルの統合(Merge)
各ラインや倉庫に点在するバラバラのExcel(.xlsx)やCSVファイルを一気に読み込み、一つの巨大なデータフレーム(仮想の表)にまとめます。
表記ゆれの正規化
srt.replaceなどの関数を使い、「(株)」を「株式会社」に統一したり、全角数字を半角に、ハイフンの有無を揃えるといった処理で完了させます。
名寄せ(Deduplication)
重複している仕入先や部品コードを特定し、最新のデータだけを残して削除します。
使うツール・手段
Google Colab
環境構築が不要でブラウザだけでPythonが動き、Excelのアップロードも簡単です。
pandasもすぐに使える状態で、最初の環境構築でつまづく時間を無くします。
AIの活用
「ChatGPT」や「Claude」などのAIでPythonコードを書かせます。
「このExcelのA列にある表記ゆれを統一するPythonコードを書いて」と指示し、
出てきたコードをColabに貼り付けて実行します。
Pythonを使うメリット
VBAのように「Excelを開いて、マクロを実行して……」という手間すら不要になります。
数万行のデータでも、数秒で処理が終わるため、
「修正してはアップロード、エラーが出てまた修正」というループから抜け出せます。
実際、多くのDXプロジェクトでは
「Excel作業をPythonで置き換える」ことが最初の成功体験になります。
【解決策②】Dify(AI)で「中身のないマスタ」を補完する
Pythonが「既にあるデータの整形」が得意な一方で、
Difyは「足りない情報を外部から取ってくる・推論する」ことに長けています。
DifyはAIをフローチャートのように繋いで動かす「ノーコードAIプラットフォーム」です。
Difyで具体的にやること
Webスクレイピング連携
「部品型式」をAIに渡し、Web検索やAPIと連携させることで、
メーカーサイトなどから仕様情報を取得しマスタに補完することも可能です。
曖昧なデータの分類(LMM分類)
担当者の「メモ書き」のような品名から、AIが
「これはJIS規格のボルトだな」
「これは消耗品のグリスだ」
と判断し、システム用のカテゴリコードを割り振ります。
画像からのデータ化
現場の古い「手書き台帳」や「部品タグ」の写真をAIに読み取らせ(OCR)、マスタの項目にマッピングします。
ノーコードの特徴
可視化されたフロー
- データを読み込む
- AIが考える
- Excelに出力する
という流れがアイコンで繋がっているため、プログラミングができなくても
処理のロジックが直感的に分かります。
エラーが出た箇所も視覚的に分かりやすいため、プログラミング知識がなくても
構築や運用がしやすいところがポイントです。
API連携が容易
導入するSaaSにAPI(システム同士の窓口)があれば
そもそもExcelを介さず直接マスタを流し込む仕組みも作れます。
Difyを使うメリット
- マスタに空欄があるから、カタログを確認して1つずつ入力する
- 過去の見積をひっくり返して、最新の単価と合っているかチェックする
という、手間暇のかかる単純調査をAIに丸投げできます。
なぜこの2つを組み合わせるのか?
製造現場のマスタ整備において、最も効率が良いのは
「Pythonで全体の形を整え、どうしても自動で埋まらない隙間をDify(AI)で埋める」というハイブリッド戦略です。
ITに詳しくない担当者だからこそ、手作業に時間を奪われるのではなく、
こうした「仕組み」を構築することに注力すべきです。
現場から「あの人が担当になってから、仕事がスムーズになった」と言われるDX担当への近道です。
どっちを使うべき?Python vs Dify の判断基準
「結局、今のマスタ整備にはどっちがいいの?」と迷うかもしれません。
判断のポイントは、「手元にデータがあるか、それとも頭(外)にあるか」です。
| 特徴 | Python(pandas) | Dify(AIワークフロー) |
| 得意なこと | 大量データの整形、計算、結合 | 曖昧な情報の推論、Web検索、分類 |
| 主な用途 | 10万行の表記ゆれを一括修正 | 品名から「消耗品か資産か」を判断 |
| 処理スピード | 極めて速い(数秒〜数分) | AIの思考を挟むため、ややゆっくり |
| 必要なもの | 整形ルール(例:全角を半角にする) | AIへの指示(例:この型式を調べて) |
| 難易度 | 中 | 低 |
- Pythonを選ぶべきケース: 元データはあるけれど、形式がグチャグチャでシステムに取り込めないとき。
- Difyを選ぶべきケース: データ自体が不足していて、カタログやネットで調べないと埋まらないとき。
現場のDXでは、まずPythonで8割のゴミデータを取り除き、残りの2割の「AIに判断させたい部分」をDifyに投げるのが、最もコストパフォーマンスの良い勝ちパターンです。
マスタ整備完了までの「3日間」ロードマップ
「マスタ整備なんて、何ヶ月かかるか分からない」と諦めていませんか?
PythonとAIを組み合わせれば、数千件のデータも「最短 3日間」で整理が可能です。
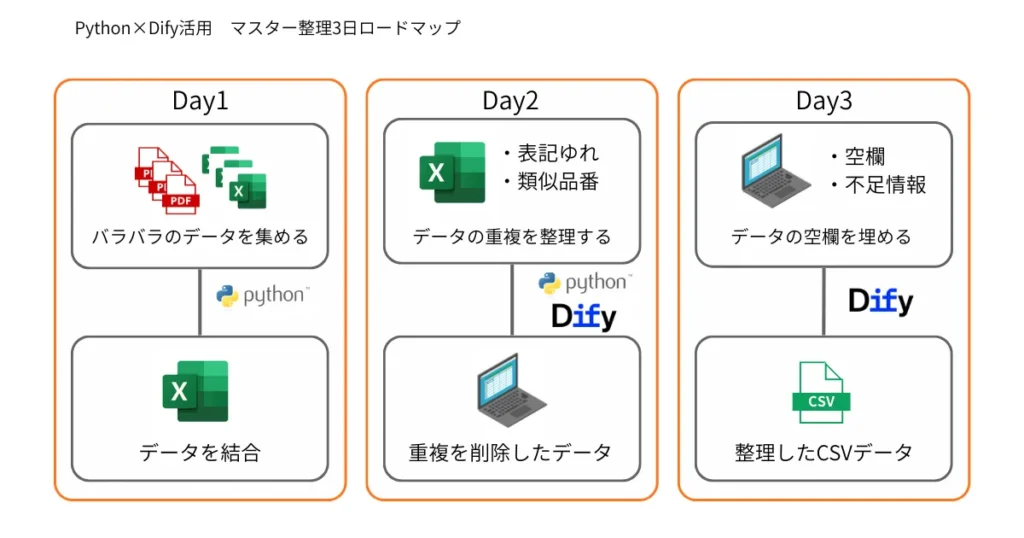
Day 1:バラバラなデータの「一カ所集約」
- 作業内容: 各所に散らばったExcelやPDF、紙の情報を一箇所に集めます。
- Pythonの出番: フォルダ内の数百個のExcelファイルを、Pythonで1つのシートに出力。同時に、全角・半角の統一や、不要な空白の削除といった「基礎的な掃除」を自動で終わらせます。
- ゴール: とりあえず「1枚の大きな表」ができる。
Day 2:重複のあぶり出しと「表記ゆれ」の解消
- 作業内容: 似たような名前で登録されている重複データを特定し、正しい名称に統一します。
- Python×AIの出番: 人間がやると見落とす「ボルト M6」と「ボルトM6(全角)」のような違いをAIが検知。類似度を計算し、「これらは同じ部品ではないですか?」とリストアップさせ、一括で置換します。
- ゴール: 重複が消え、データの「項目名」が整う。
Day 3:不足情報の「AI補助入力」とマスタ完成
- 作業内容: 「図面番号はあるが、材質が空欄」といった不足データを埋めていきます。
- Dify(AI)の出番: 部品名や図面番号をヒントに、AIが過去の関連データや仕様書から材質・価格などの欠落情報を予測・補完。最後に人間が最終チェックをして、システムにインポート可能な「生きたマスタ」が完成します。
- ゴール: システムへ投入できる「高精度なマスタ」が完成。
「3日で終わらせる」ための最大の前提条件
ここまでPythonとDifyを使ったマスタ整理の方法を話しましたが
「道具がすでに使える状態にあること」が重要です。
正直に言って、もし初日に「Pythonのインストール方法」をググるところからスタートしたら
3日のうちの丸1日が環境構築とパスの設定エラーだけで溶けてしまいます。
そうなると「3日でマスタ整備」は絶対に不可能です。
この「3日」を現実にするための裏の前提条件を正直にまとめます。
「3日」を現実にするための3つのショートカット
1. Google Colab を使う(環境構築のスキップ)
自分のPCにPythonをインストールして「ライブラリが読み込めない」と悩むのは時間が勿体ないです。
Google Colabを使えば、すぐにpandas(表データを扱えるライブラリ)が使える状態になっています。
これで環境構築の1日を短縮できます。
2. AI(ChatGPT/Claudeなど)に「型」を書かせる
ゼロからコードを書くのではなく、AIに「このExcelを読み込んで、A列の重複を消すコードを書いて」と指示し、
出てきたものを貼り付けて動かす。
この「AIコーディング」という前提があってこその3日です。
3. Difyはクラウド版(SaaS)を使う
自前でサーバーを立てるのではなく、Dify.aiのクラウド版を使えば、登録して5分でワークフローを作り始められます。
Dooker Desktopなどをインストールすればローカル環境でもDifyの起動は出来ますが
最初の設定に少し時間がかかるため、最短で作り始めるならクラウド版一択です。
Dooker Studioは小規模事業者(売り上げ1,000万ドル以下/年、従業員250人以下)であれば
無料で利用できるので、将来的にローカル環境を構築したい場合には選択肢として有効です。
【正直な補足】でも、知識ゼロだと結局は止まる
道具が揃っていても、基礎知識がゼロだとここで詰まります。
- AIが書いたコードをColabに貼ったが「ファイルが見つかりません」というエラー(パスのミス)が出て、直し方が分からず1日が終了。
- DifyでAPI連携の設定画面を見たが、「JSON」や「ヘッダー」という言葉の意味が分からず、設定を諦めてしまう。
だからこそ、「Pythonの基礎」を最低限身につけておくことが重要です。
AIは強力な補助ツールですが、エラーの原因を理解し修正できるのは人間だけです。
Pythonの基礎があるだけで、マスタ整備のスピードは何倍にも変わります。
Pythonのスキルを習得するには?
ここまでマスタ整備の効率化について解説してきましたが、やはり鍵となるのは
「Pythonという道具を、どれだけ自分の手足のように動かせるか」です。
AI(ChatGPTやDify)は強力な助っ人ですが、彼らに正しく指示を出し、
出てきた結果の正誤を判断するには、あなたの中に「Pythonの基礎」という土台が不可欠です。
- 「何から手をつければいいか分からない」
- 「現場で使えるレベルまで最短で到達したい」
という方のために、具体的な90日間の学習ルートを別の記事で詳しく解説しています。
- 環境構築で挫折しないためのコツ
- 製造現場でまず覚えるべき3つのライブラリ
- 実務に落とし込むためのステップアップ法
マスタ整備地獄を抜け出す第一歩としてチェックしてみてください。
➔ 【関連記事】DX担当がPythonを武器にするまでの90日ロードマップ
まとめ:マスタ整備を「DXスキルの成長痛」に変えよう
DXの成否を分けるのはシステムではなく、地味で大変な「マスタ整備」です。
これを手作業の苦行としてやり過ごすのか、
それともPythonやDifyといった武器を習得するための絶好のチャンスと捉えるか。
その選択が、今後のあなたの業務の幅を大きく変えます。
- Pythonが使えれば、膨大なデータの整形や統合が数秒で終わる。
- Difyを使いこなせば、AIに調査や分類を丸投げできる。
これらを組み合わせることで、今まで「数週間かかる」と諦めていた改善が、たった数日で実現できるようになります。
自社の現場を一番よく知るあなたが技術を持つこと。
それこそが、現場にフィットした「本物のDX」を生む最短ルートです。
私自身も、「いかに楽をして成果を出すか」を追求する「ズボラDX」を検証しています。
製造現場でも保守がしやすい、ノーコードに拘ったDify活用術については、
こちらの「ズボラDX研究所」で発信しているので、ぜひ覗いてみてください。









