

第1話では、ナレッジ読み込みの壁に阻まれてAIに嘘をつかれた話をしました。

今回の第2話では、ズボラDXレポートの「システム設計図」を公開します。
なぜこの組み合わせなのか、なぜプログラミングではなくノーコードに拘るのか。
製造現場ならではの理由と、ツールの特徴。
ズボラDX全自動レポートの出来るまでの仕組みを解説します。
ズボラDXレポートの作成メンバー(ツール)
レポート作成を全自動にするために、メンバー(ツール)を選定しました。
Make
決まった時間に起動し、データを持ち運ぶ役割です。

月曜の朝8時に出社するよ!
出社したら新しい日報があるか本棚に見に行くよ!
あったら事務室にもっていくね。
別々の場所にある資料(データ)や作業者(AI)を繋ぐ役割を買って出てくれる優秀なスタッフ。
きっとコミュ強。
Dify
決められたタスクを爆速でこなす優秀な事務員。

データの解析、資料のまとめ。
全部わたしにお任せください!
とっても仕事が早いけど、デスクから一歩も動かない。

資料がないから何もしません。
資料取りにいけって?
それ、私の仕事なんですか?
仕事の線引きするタイプ。
Google Drive(書庫)
日報を入れておく場所。

作業が終わったら本棚に
日報を入れておこう
作業者(人間)はここに入れておくだけでMakeが事務所(Dify)に持って行ってくれます。
Google Sheets(レポート)
Difyが解析したデータをまとめた資料。
ただDifyは解析結果しか出してくれないので
AIが解析した結果をMakeがGoogle Sheetsにまとめてくれます。

簡単なコピペくらいなら
やっておくね
Looker Studio(掲示板)
出来上がったレポートを張り出しておく掲示板の役割。
過去のレポートも全部保管してあるので
好きな期間のレポートを貼りだすことが出来ます。
ズボラDXレポートが出来るまで
このツールを使ってどのようにレポートを作ろうとしているか
出来上がるまでの全体の流れを解説します。
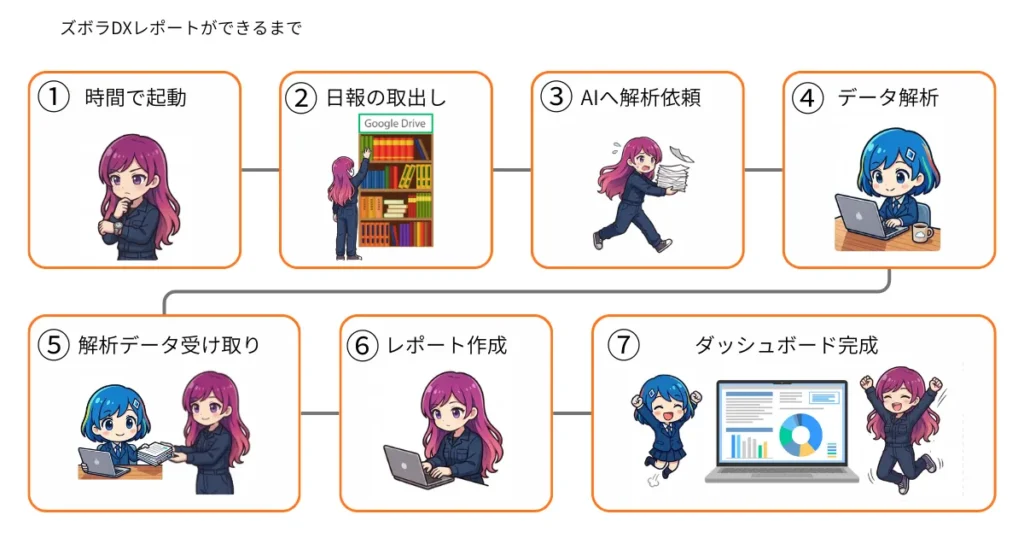
- 決まった時間(毎週月曜8時と過程)にMakeが起動
- Google driveの日報保存フォルダを見て、新しい日報があればデータを抽出
- Difyへデータを運び、解析プロセスへ
- Dify内でAIが日報(Excel、PDF)を読み取り、単価マスターと連動して計算
- Difyが解析したデータCSVをMakeが受け取る
- MakeがGoogle SheetsにCSVの内容を転記する
- Looker Studioと連携するとダッシュボードが完成
ここまでで人がやることは、Google driveの指定フォルダに
日報(Excel、PDF、手書きスキャン)を入れるだけ。
毎週月曜日にレポート作成し、Looker Studioに見に行ったら1週間分のデータが
ダッシュボードで見えるようになっているという仕組みを考えました。
月曜の朝、コーヒーを飲んでいる間にAIがレポートをまとめてくれる。
これこそがズボラDXの目指す姿です。
ズボラDXの情報の生産ライン
バラバラに存在するツールを一つにつなぎ、情報の流れを可視化します。
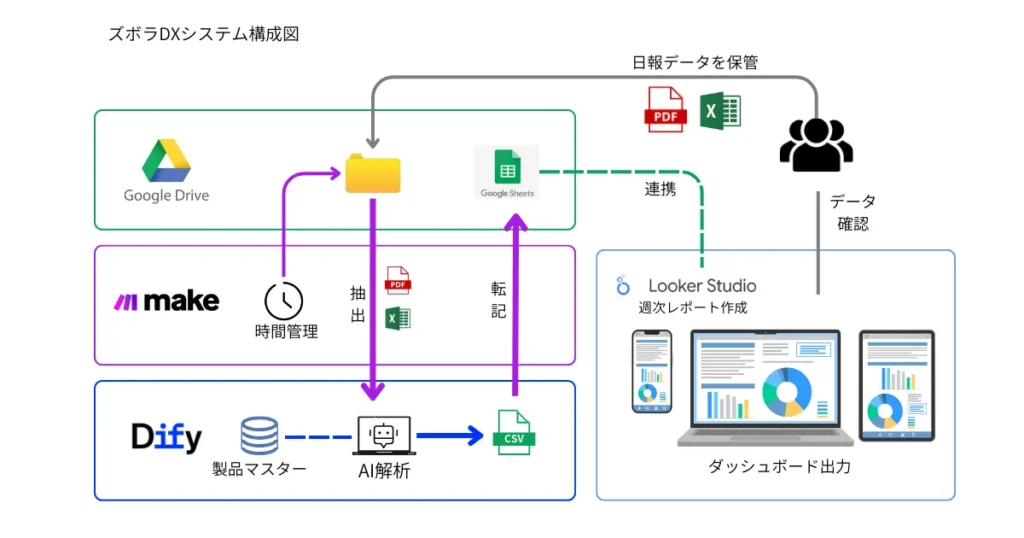
- 書庫(Google Drive): 日報を格納しておく書庫、および本棚(フォルダ)
- 連携(Make): 自動で起動、データの流れを作る
- 解析(Dify): AI解析・データ抽出
- データ保管資料(Google Sheets): データの蓄積・修正(人の手で変更可能)
- 掲示板(Looker Studio): レポート・ダッシュボード生成
今まで人の手で集計すると数時間かかっていた作業を
AIによって自動化することで、人が本来の生産や改善といった業務に集中できる環境になります。
また、日報から読み解くのが難しい情報(深夜に不良が多い、どの機械が不良が出やすい)なども
AIが分析して可視化することが出来ます。
ズボラDXはなぜ「ノーコード」に拘るのか
Pythonなどの言語を使えば、レポート作成の仕組みも構築できますしより高度なことも可能です。
しかし、あえてノーコードを選んだのには、製造業特有の理由があります。
理由1:保守の民主化
「作った人が辞めたらシステムが動かない」という属人化は、DXにおいて最悪のシナリオです。
Pythonで構築すると、エラーが出ても何を直せばいいのかが分からないブラックボックス化する恐れがあります。
MakeやDifyなら、画面を見れば「ここを直せばいい」と直感的に理解できるので
誰でもメンテナンスが出来ることこそが製造業において重要と考えています。
理由2:改善スピードが桁違い
日報のフォーマット変更や項目追加、もしくは生産品目によってフォーマットが変わるなど
製造業においてはよくあることです。
その都度コードを書き直してテストして再デプロイするのは効率も悪く、その間業務に支障がでます。
ブロックを1個追加するだけで対応できるノーコードツールだからこそ、現場の改善速度を上げます。
理由3:誰でも再現できる「型」の提供
Pythonなどのプログラミングは専門知識も必要で、自社に詳しい人がいないと構築できません。
DifyやMakeであれば、プログラミングスキルが無くても直観的な操作が可能です。
「読者が同じ手順で、明日から自社で再現できること」
この再現性こそが、ズボラDX研究所の価値だからです。
理由4:多拠点展開もしやすい
Make、Difyともに一度構築してしまえば設定内容をエクスポート(抽出)して
別の拠点のアカウントにインポート(挿入)するだけで同じ環境が構築できます。
多拠点展開している製造現場でも、コピペ感覚で導入が展開できます。
理由5:クラウドでの一元管理
運用の途中で、仕様を変更したいとなった場合でも
Dify、Makeはクラウド上で変更できるため、全拠点の仕組みを簡単に変更できます。
このメンテナンス性の良さこそ、クラウド型を使うメリットと言えます。
Pythonを選ばなかった3つの理由
もちろん、Pythonでも同じ仕組みは作れます。
AIを自在に操るならPythonは最強の道具です。
しかし、今回の「ズボラDXレポート」で私がPythonを選択しなかったのに、3つの現実的な理由があります。
1. 「動かす場所」の確保が意外と重い
Pythonで作ったプログラムを24時間・多拠点で動かすには、「サーバー」が必要です。
自社でサーバーを立てるか、AWSなどのクラウドを契約するか。
いずれにしても、OSのアップデートやセキュリティ対策といった、本業(製造)とは無関係な
「ITインフラ管理」という仕事がもれなく付いてきます。
MakeやDifyなら、ブラウザを開くだけでそこが「情報の生産工場」になります。
インフラ管理はプラットフォームにお任せできるのです。
2. 「拠点の壁」をコピペで超えられない
拠点が1工場、2工場、3工場と増えたとき、
Pythonだと各環境の「環境構築」や「ライブラリのバージョン合わせ」に追われることになります。
一方、MakeやDifyは「設定ファイルの書き出し・読み込み」だけで、一瞬でコピーが完了します。
またシステムのメンテでも1箇所修正すれば、全拠点のシステムをネット越しに一括アップデートできる。
このスピード感は、多拠点展開において圧倒的なアドバンテージです。
3. 保守をだれがやるのか
「コードが書ける人」しか直せないシステムは、現場では「ブラックボックス」と呼ばれます。
担当者が変わった瞬間に、そのシステムは「触れてはいけない遺物」になってしまう。
ノーコードは、「画面を見れば仕組みがわかる」ため、保守のハードルが下がります。
【それでもPythonを学びたい方へ】
もちろん、AIの仕組みをより深く理解し、もっと複雑なカスタマイズ(独自の画像解析など)を
したい場合には、Pythonの知識は大きな武器になります。
「自作のその先」を目指したい方は、こちらの学習ロードマップも参考にしてみてください。

「ズボラDX」導入・運用コスト目安(月額・税込)
1. ツール料金(定額分)
事業規模に合わせて、現実的なプランを選択しています。
事業規模や、データの処理量(日報の枚数)によって最適なプランが変わります。
下記の表は目安として参考にしてください
| 項目 | 個人・テスト | 小規模(10-30名) | 中規模以上(30名〜) |
| Make | 0円 (Free) | 約1,500円 (Core) | 約2,800円 (Pro) |
| Dify (Cloud) | 0円 (Sandbox) | 約8,900円 (Professional) | 約23,000円 (Team) |
| Google Drive | 0円 | 約680円 (Starter) | 約1,360円 (Standard) |
| Docker費用 | 0円 | 0円 | 約3,000円 (Docker Business)※1 |
| 定額合計 | 0円 | 約11,080円 | 約30,160円 |
※1:従業員250名以上、または売上$10M以上の企業でDocker Desktopを利用する場合。
2. AI使用料(従量課金分)
Gemini 1.5 Flashを使用し、日報1枚あたり「入力1,000文字+出力500文字」程度を想定。
※1ドル=150円、100万トークンあたり$0.1(入力)/$0.3(出力)で計算。
| 規模 | 1日の日報枚数 | 月間枚数(20日) | 月間コスト目安 |
| 小規模 | 20枚 | 400枚 | 約30円〜50円 |
| 中規模 | 50枚 | 1,000枚 | 約80円〜150円 |
| 大規模 | 500枚 | 10,000枚 | 約800円〜1,500円 |
【結論】AI使用料は「ほぼ無視できるレベル」で安いです。
製造業のテキスト解析(日報)レベルであれば、高額なGPT-4oを回し続けない限り
コストの主役はAI代ではなく「ツールの月額基本料」になります。
各ツールの「規模別」選び方ポイント
1. Make:人数ではなく「回数」で決まる
Makeの料金は「接続人数」ではなく、「月間で何回プログラムを動かしたか(Ops)」で決まります。
- 個人: 月1,000回まで無料。週1回のレポートならこれで十分。
- 小規模: 月1万回(Core)。毎日複数のラインから日報が飛んでくるならこのプラン。
- 中規模: 複雑な分岐(エラー時のリトライ処理など)を組むなら、制限のないProが推奨です。
2. Dify:セキュリティと「管理」で決まる
Difyは2026年現在、クラウド版とセルフホスト(自社サーバー)で大きく分かれます。
クラウド版「プロフェッショナル」がおすすめ。ベクターDB(知識データ)の容量が増え、実用性が上がります。
クラウド版Teamかセルフホストがおすすめ。
「社外のサーバーに日報を置きたくない」という製造業特有のセキュリティ要件が出てきます。その場合は、社内サーバーやVPSにDocker Desktop等を用いて構築する「セルフホスト」一択。
クラウド版の無料のSandboxプランは、実行回数が200回(月ではなく、200回使い切ったらおわり)なので
試運転やテストではいいですが、実用は出来ません。
3. Docker Desktop:ローカル環境でDifyを使うのに必要。
ローカルPCや社内PCでDifyを動かす場合、Docker Desktopが必要です。
クラウド版と違って手軽ではありませんが、Docker DesktopでDifyを動かす場合は、
クラウド版Difyの利用料金がかからないメリットもあります。
- 注意: 従業員250人以上、または年間売上1,000万ドル以上の企業の場合、Docker Desktopは有料(月額約3,000円〜)になります。中規模以上の事業者はここを見落としがちなので注意が必要です。
次回予告:実際に作る(Dify再チャレンジ編)
ここまで、第2話ではノーコードツールに拘った設計思想を紹介しました。
次回・第3話では、第1話で無惨に砕け散った「Difyの知識習得(ナレッジ読み込み)」に再チャレンジしました。
ナレッジ習得の壁をどう打破するのか、検証した内容を公開しています!

▼ズボラDX研究所の全話はこちらから読めます。






