

「紙の日報を放り込めば、一瞬で単価まで計算されたCSVが手に入る……!」
そんな淡い期待をしていた時期が、私にもありました。
しかし、現実は甘くありません。
AIといえど、こちらがお膳立てをサボれば、驚くほど融通が利かないのです。
今回は、そんなAIの「頑固さ」に振り回されて試行錯誤し
「二段構え」という解決策にたどり着くまでの記録です。
▼ノーコードツールで挑戦するDXシリーズはここに全話掲載しています!

Difyのナレッジ(RAG)が動かない:AIは意外と「空気が読めない」
製品マスターを「ナレッジ」として学習させ、日報画像をアップロードした私を待っていたのは、
AIからの無慈悲な回答でした。

「ナレッジの【単価リスト】」が今回のコンテキストでは
提供されていないため、**良品数 × 単価の計算および
生産金額の算出は現時点では実行できません。
いや、ある。絶対にある。
ナレッジ(CSV)にある品番が、なぜか目の前のAIには見えない?
このナレッジの壁を破らないことには日報を読み取るだけしかできない・・・。
一先ず現状の設定を整理します。
現状のDify設定状況
まずはおさらい(ちゃんと公開していなかった)として
Difyの設定を共有します。
アプリの名前は日報解析がんばるちゃん(仮称)
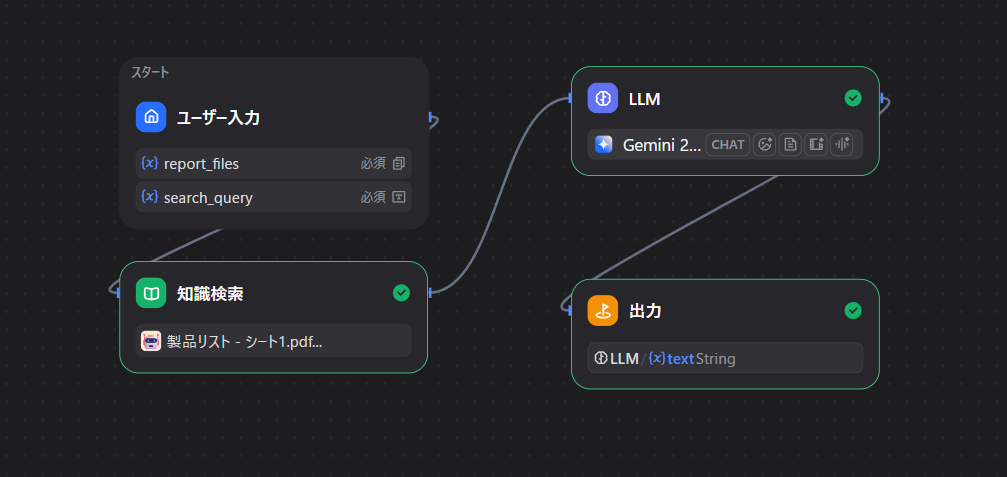
Difyで組んでいるワークフロー(業務の流れ)はこんな感じにしています。
- ユーザー入力:日報データをアップロード
- 知識検索:ナレッジ(製品リスト)を保管、参照する書庫の役割
- LLM:AIで日報の内容の解析と、ナレッジのリストから単価を引っ張って計算する仕組み
- 出力:解析結果の提出
こんな流れでひとまずは作って動作確認をしました。
▼動作確認した結果は1話に詳しく書いています!

Difyのナレッジ(RAG)が、失敗する理由
Difyにおいて、独自の外部データ(今回で言えば製品単価マスター)を参照させる「ナレッジ(RAG)」は、まさにDXの要です。
ワークフローは合っているはず。
しかし、実行ボタンを押してもナレッジ情報は読み取れない。
ワークフローのログを見ると、ナレッジノードを通過したときに
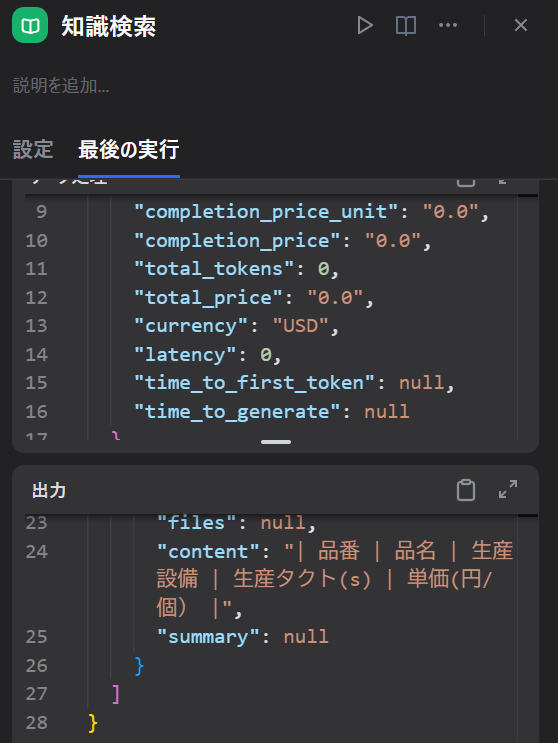
きちんとナレッジ(製品リスト)の中身をチェックしているのは確認できました。
ナレッジの設定は合ってるはず。テストでは「品番=単価」が繋がっているのに…
何度やってもナレッジを読み込めないので
ナレッジ単体で動作確認をしてみることに。
Difyのナレッジ管理画面には、登録したデータが正しく検索できるか試す「クエリテスト」機能があります。
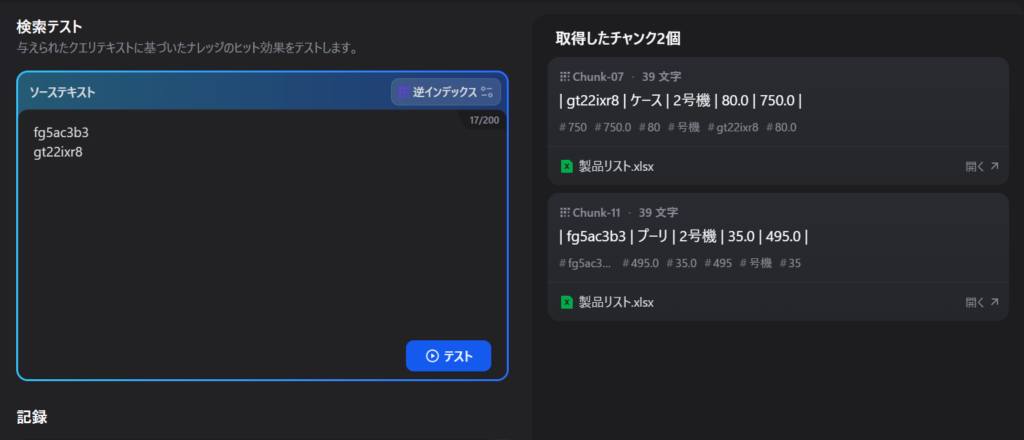
手入力で製品リストに登録している品番を打つと、ちゃんと製品リストから引っ張ってきます。
つまり、ナレッジは正常に動作はしていて「準備万端、いつでも来い!」という状態。
それなのに、ワークフローとして繋げた途端に、ナレッジは反応せず。
「ナレッジの【単価リスト】」が今回のコンテキストでは
提供されていません。
とAIに言われてしまう。
私は開始ノードに記述した「ある一文」が、AIを混乱させているのではないかという疑念を抱き始めました。
検索クエリの誤解:「製品リスト」という品番なんて存在しない
原因を探る中で、私は開始ノード(ユーザーが指示を出す最初の地点)のプロンプトを読み返しました。
そこには、良かれと思ってこう記述していました。
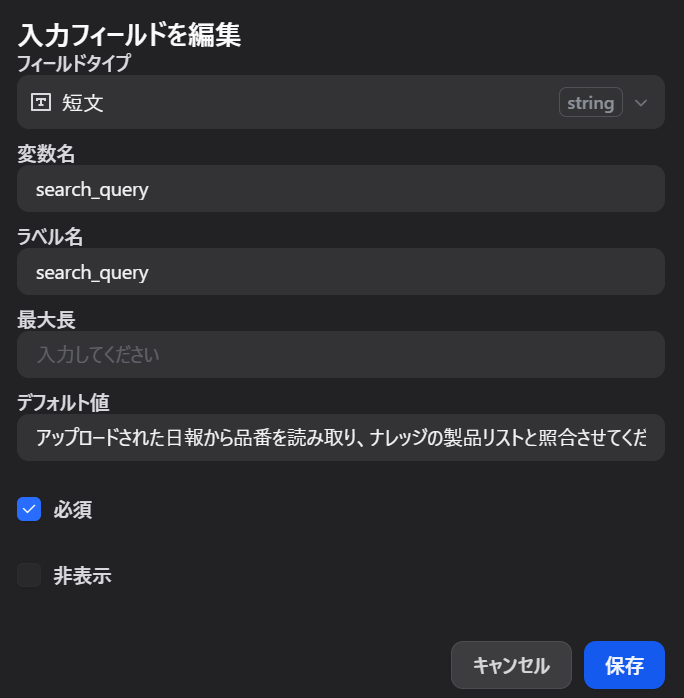
「アップロードされた『日報』から品番を読み取り、ナレッジの製品リストと照合させてください」
実はこれこそが、AIを迷宮に叩き込んでいた元凶でした。
Difyのナレッジノードに情報を渡す際、
AIは「渡されたテキストの塊」をそのまま検索クエリ(検索ワード)として扱おうとします。
つまりAIの中では
ふむふむ、ユーザーは
「アップロードされた『日報』から品番を読み取り、ナレッジの製品リストと照合させてください」
という品番を探してほしいんだね!
という、とんでもない勘違いをしていたわけです。

「アップロードされた『日報』から品番を読み取り、ナレッジの製品リストと照合させてください」
っていう品番は製品リストにないよ?
「製品リスト」という名の製品なんて、ナレッジには1行も登録されていません。
結果、ナレッジは「一致なし」という判断をしてしまったわけです。
【検証】開始ノードに品番を打ち込むとRAGは動くか
search_queryの欄に手入力で品番を入れてテスト
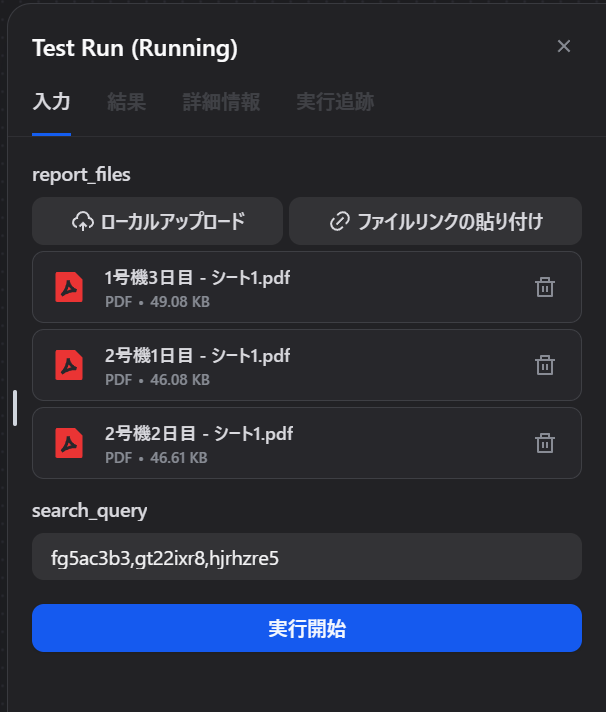
日報PDFを3枚入れてみて、search_queryに品番を手入力して実行してみます。
RAGから単価取得は成功
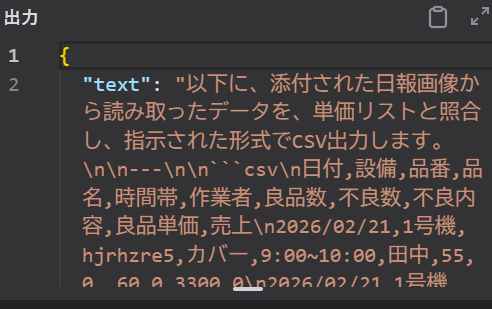

以下に、添付された日報画像から読み取ったデータを、単価リストと照合し、指示された形式でCSV出力します。\n\n—\n\n“`csv\n日付,設備,品番,品名,時間帯,作業者,良品数,不良数,不良内容,良品単価,売上\n2026/02/21,1号機,hjrhzre5,カバー,9:00~10:00,田中,55
・・・以下略
ちゃんと読み取れました!ようやく、読み取ることが出来ました!!
ただここでも問題が・・・。
出力:2026/02/21,1号機,hjrhzre5,カバー,9:00~10:00,田中,55,0,,60.0,3300.0
出来高55(日報から読み取り)×60円=3,300円と出力されてますが

上記、製品リストの生産タクトの数字を単価と勘違いして、計算していました・・・。
簡単な解決策として思い浮かぶのは
- 5列目が単価だから5列目の数字で計算してとAIに指示する
- 生産タクトを製品マスタから除外する
- タクトや単価の欄の数字に単位を入れる
ただ、このやり方をすると製品マスタのフォーマットを固定したり
わざわざ出来上がっているマスタに単位を入れるのもズボラとは言えない・・・。
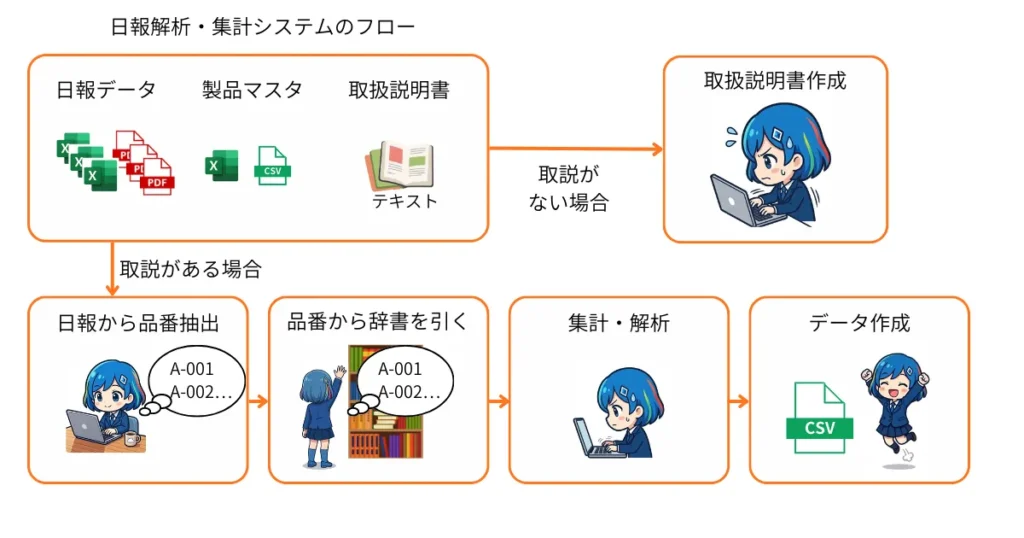
製品マスタをAIに理解させる「取扱説明書」作戦
master_definitionの作成
今はナレッジから読み込んだデータをAIが理解していないから
まずは製品マスタの中身をAIに理解させるための「取扱説明書」を作ればいいんじゃないか?
取扱説明書があれば、どの列に何が入力されているかAIも理解できるはず。
Excel製品マスタの列構造をAIで自動解析
ただ取扱説明書を人の手で作るのもめんどくさい・・・。

取説もAIに作ってもらおう!
ということで、試してみました。
これだけ見てもわけわからないよ!って人もいると思うので下の画像がイメージ
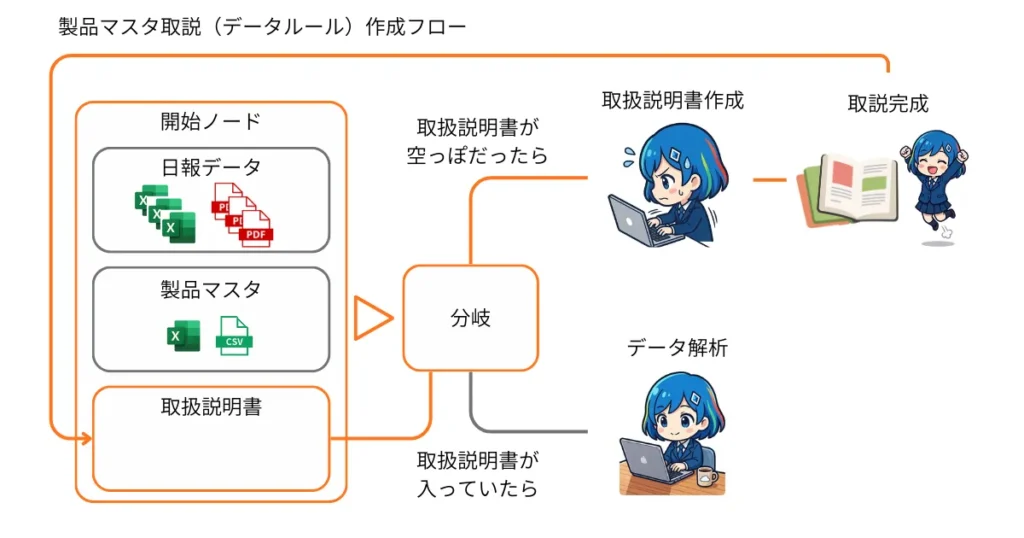
開始ノードに取扱説明書の欄(master_definition)を設けて、そこにデータがあるかどうかで分岐させるイメージです。
一度ここで取説を作ってしまえば、あとはそのルールで解析すればデータの間違いは起きないはず・・・。
いざ実行 take1
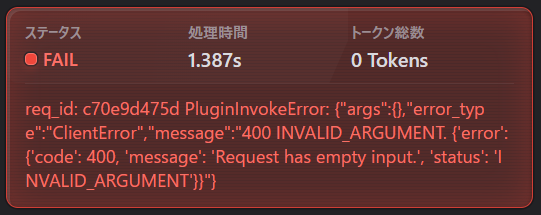
早速エラーにぶち当たる。
400エラー(こちらからのリクエストのエラー)が出ていますね・・・。
一回GeminiからChatGPTにモデルを変更して再トライしてみます。
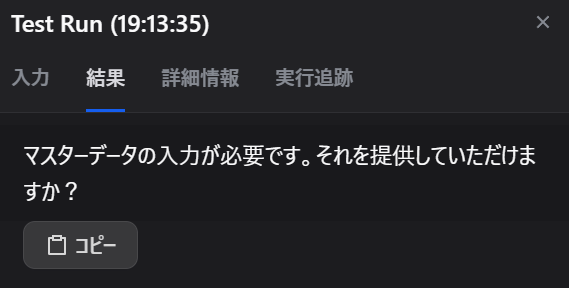
masterデータを読み込めない・・・?
Excelデータが読めない可能性もあるので、間にテキスト抽出を挟んでみます。
いざ実行 take2
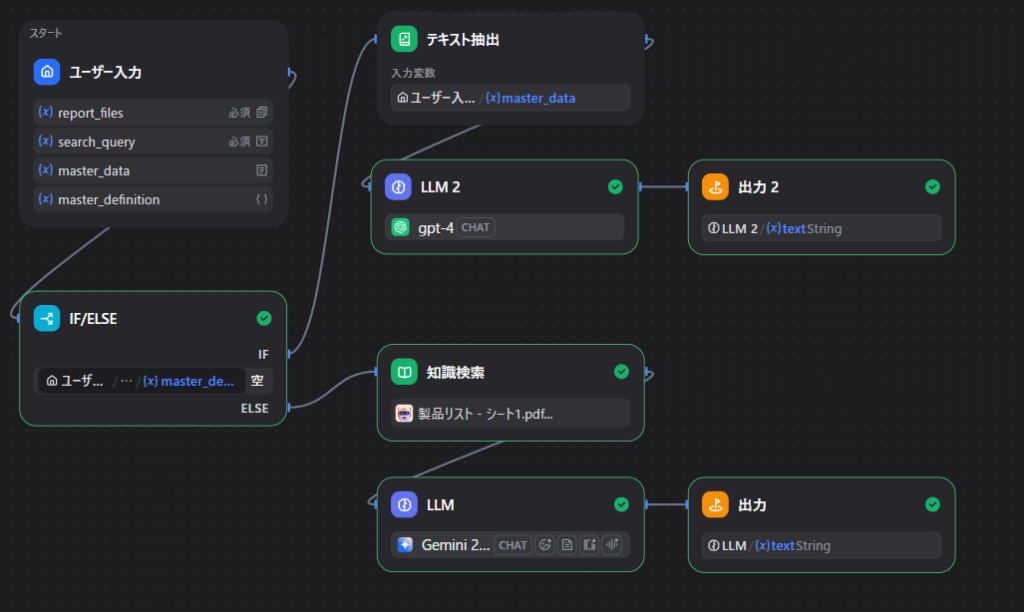
{ “id_col”: 0, “name_col”: 1, “mach_col”: 2, “tact_col”: 3, “price_col”: 4 }
ちゃんとExcelの中身を読み込んでくれました!
一番左(0列目)から
- ID(品番)
- name(製品名)
- mach(機械)
- tact(生産タクト)
- price(製品単価)
ちゃんと出力してくれてますね!
これを開始ノードの取説(master_definition)に入れておけば、きっと解析できるはず。
いざ実行 take3
承知いたしました。添付された3つの手書き日報のスキャン画像を読み取り、ナレッジの単価リストと照合し、ご指定の形式でCSVデータを作成します。

おお!出来たか!?
単価リスト(ナレッジより)
| 品番 | 品名 | 生産設備 | タクトタイム | 単価 |
|---|---|---|---|---|
| pug2fnbr | カバー | 1号機 | 50.0 | 160.0 |
| gt22ixr8 | ケース | 2号機 | 80.0 | 750.0 |
| hjrhzre5 | カバー | 1号機 | 60.0 | 842.0 |
データ抽出と計算結果
日報1: 2026年 2月 19日
- 生産設備: 2号機
- 品番: gt22ixr8
- 品名: ケース
- 単価: 750.0
| 時間 | 作業者 | 良品数 | 不良数 | 不良内容 | 単価 | 生産額(良品数×単価) | 損失額(不良数×単価) |
|---|---|---|---|---|---|---|---|
| 9:00~10:00 | 山田 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 10:00~11:00 | 山田 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 11:00~12:00 | 山田 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 13:00~14:00 | 山田 | 38 | 4 | フラッシュ | 750.0 | 38 × 750.0 = 28500.0 | 4 × 750.0 = 3000.0 |
| 14:00~15:00 | 山田 | 38 | 4 | フラッシュ | 750.0 | 38 × 750.0 = 28500.0 | 4 × 750.0 = 3000.0 |
| 15:00~16:00 | 山田 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 16:00~17:00 | 山田 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 18:00~19:00 | 佐藤 | 38 | 4 | フラッシュ | 750.0 | 38 × 750.0 = 28500.0 | 4 × 750.0 = 3000.0 |
| 19:00~20:00 | 佐藤 | 39 | 3 | フラッシュ | 750.0 | 39 × 750.0 = 29250.0 | 3 × 750.0 = 2250.0 |
| 20:00~21:00 | 佐藤 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 | |
| 21:00~22:00 | 佐藤 | 42 | 0 | 750.0 | 42 × 750.0 = 31500.0 | 0 × 750.0 = 0.0 |
とりあえず日報3個読み込んだうちの1個だけを上に記載しましたが、3枚とも出力出来ました。
しかも、この表全部AI出力をそのままコピペしただけです。
CSVと合わせて表まで作ってくれた・・・優秀ちゃん。
ここまでで、
- ナレッジ読み込みの問題
- 製品リストの単価間違いの訂正=取説作成
- 取説作成のExcel読み込み問題
これらを解決することが出来ましたが、肝心の問題が解決出来ていません。
それは「開始ノードに品番を手入力している」問題です。
こんな手入力なんてやってたら、とてもズボラを名乗れません。
なのでこの品番抽出もAIにやってもらいましょう!
品番抽出LLMを挟む二段構えワークフローの構築
日報➔品番抽出をAIにテストさせてみる
ナレッジへの指示が「品番一致」が必要ならば
ナレッジの手前でAIに、日報から品番のみを抽出してテキストにすればいいのでは?
ということで、ワークフローを更新してみます。
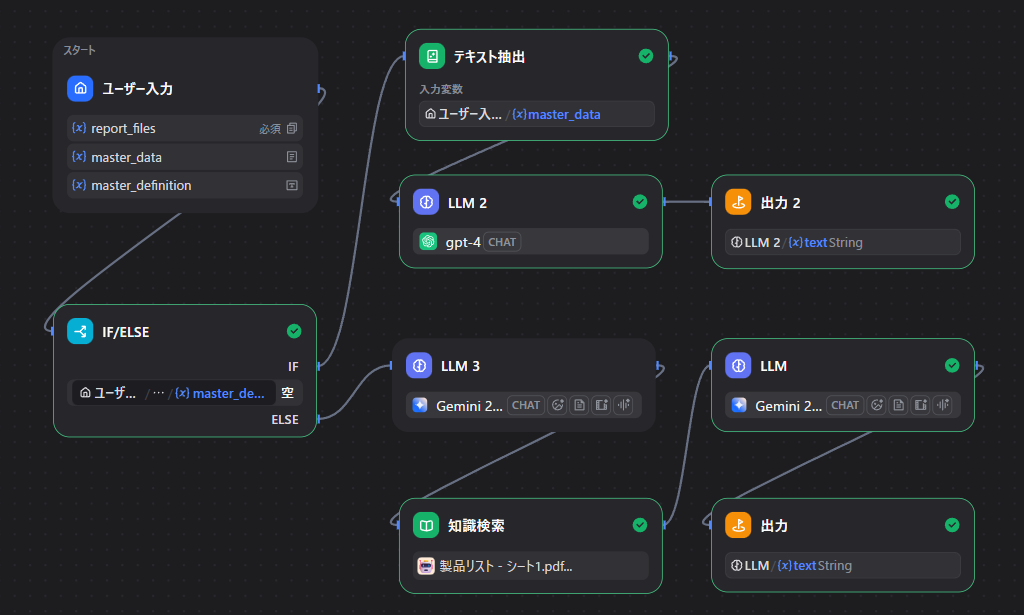
なんだかごちゃごちゃしてきました・・・。
同じ事務所(Dify)に事務員(AI)が3人いるような配置ですね。
とりあえず実行 take1
添付された3枚の手書き日報のスキャン画像を読み取り、
ナレッジの単価リストと照合してCSVを作成しました。
単価リスト(ナレッジ)
| id_col | name_col | mach_col | tact_col | price_col |
|---|---|---|---|---|
| gt22ixr8 | ケース | 2号機 | 80.0 | 750.0 |
| fg5ac3b3 | プーリ | 2号機 | 35.0 | 495.0 |
| hjrhzre5 | カバー | 1号機 | 60.0 | 842.0 |
一応出力できたものの、さっきと同じ日報なのに「プーリ」という誤った品番が出てきました。

はぁ、やっぱりAIでは
読み取りも間違えるのか
と、ここで日報を見返したら
「fg5ac3b3、プーリ」とちゃんと日報に書いてます。
つまり、さっき手入力で私が打っていた品番が日報と間違えてたということ。
これで実証されましたね!人の手だと失敗するようなこともAIならちゃんと読み取れることが!
疑ってごめんなさい。
画像2 (2026年2月20日) のデータ処理
- 日付: 2026/02/20
- 生産設備: 2号機
- 品番: fg5ac3b3
- 品名: プーリ
- 単価: 495.0 (品番
fg5ac3b3と照合)
| 時間 | 作業者 | 良品数 | 不良数 | 不良内容 | 良品額 (良品数 * 495.0) | 損失額 (不良数 * 495.0) |
|---|---|---|---|---|---|---|
| 9:00~10:00 | 山田 | 95 | 0 | 95 * 495.0 = 47025 | 0 * 495.0 = 0 | |
| 10:00~11:00 | 山田 | 95 | 0 | 95 * 495.0 = 47025 | 0 * 495.0 = 0 | |
| 11:00~12:00 | 山田 | 93 | 2 | ショート | 93 * 495.0 = 46035 | 2 * 495.0 = 990 |
| 13:00~14:00 | 山田 | 93 | 2 | ガス | 93 * 495.0 = 46035 | 2 * 495.0 = 990 |
| 14:00~15:00 | 山田 | 93 | 2 | ガス | 93 * 495.0 = 46035 | 2 * 495.0 = 990 |
| 15:00~16:00 | 山田 | 89 | 6 | ガス | 89 * 495.0 = 44055 | 6 * 495.0 = 2970 |
| 16:00~17:00 | 山田 | 89 | 6 | ガス | 89 * 495.0 = 44055 | 6 * 495.0 = 2970 |
| 17:00~18:00 | 佐藤 | 92 | 3 | ショート | 92 * 495.0 = 45540 | 3 * 495.0 = 1485 |
| 18:00~19:00 | 佐藤 | 92 | 3 | ショート | 92 * 495.0 = 45540 | 3 * 495.0 = 1485 |
| 19:00~20:00 | 佐藤 | 92 | 3 | ガス | 92 * 495.0 = 45540 | 3 * 495.0 = 1485 |
| 20:00~21:00 | 佐藤 | 92 | 3 | ガス | 92 * 495.0 = 45540 | 3 * 495.0 = 1485 |
| 21:00~22:00 | 佐藤 | 92 | 3 | ガス | 92 * 495.0 = 45540 | 3 * 495.0 = 1485 |
この表もAI出力をそのままコピペしました。
完璧、、私が品番ミスしてもAIはミスしてないよ・・・。
このナレッジへの品番抽出AIはtake1で一発OK出してくれました。めでたしめでたし。
このワークフローを図解で整理するとこんな感じです。
今回の検証結果:AIは「空気を読まない」が「正確に読み取る」
AIは「不安定」ではなく「人間より正確な鏡」だった
今回の検証で衝撃だったのは、AIが算出したデータが私の予想と食い違ったときのことでした。
「またAIが読み取りミスをしたか……」と疑いながら、
日報の原本と自分の手入力を突き合わせた結果、間違っていたのはAIではなく、私の「手入力」でした。
AIは、人間のように「たぶんこうだろう」という思い込み(バイアス)を持ちません。
「AIは不安定だ」という先入観を持っていましたが、
実際には人間よりもはるかに正確に現実を映し出す鏡であることを、身をもって知らされました。
「既存マスタ」は変えない。AIに「読み方」を学ばせる現場ファースト
今回のもう一つの大きな収穫は、既存のExcelマスタに一切手を加えなかったことです。
通常、システム導入となれば「システムが読みやすいようにマスタを加工してください」
と現場に強いるのが常識。
しかし、それは現場の負担を増やすだけで、結局は使われないツールを生む原因になります。
今回は、AIにマスタそのものを解析させ、
「何列目が単価か?」という取説(JSONデータ)を自動生成させることで、
マスタのフォーマットを固定しない「自由な設計思想」を実現しました。
「手入力=悪」という確信
品番1文字、数字1つの入力ミス。
現場では小さなミスに見えても、集計され、経営判断の材料になったとき、それは大きな歪みとなります。
「手入力」を徹底的に排除し、AIに「眼」と「脳」を代行させること。
一見ズボラのように見えますが、人の手を極力介さないことが情報の正確性を上げると改めて感じました。
まとめ:Difyでつくる現場DXの可能性
マスタの「取説」自動生成が、運用を劇的に楽にする
マスタを読み込ませるたびに、人間が「えーと、単価はE列で……」と設定し直すのは、ズボラとは言えません。
「マスタの読み方(取説)」すらもAIに作らせるという「二段構え」のワークフローこそが、
現場の変化に柔軟に対応できる、息の長いシステムを作る鍵と考えてます。
Difyというノーコードツールを使い倒した結果、AIを単なる「計算機」としてではなく
「現場の意図を汲み取って整理する優秀な事務員」として配置することができました。
次回予告:「3枚の成功」から「100枚の自動化」へ
Difyというツールを使ってプロトタイプは完成しました。
しかし、本当のズボラはここからです。
- 「3枚の日報」なら1分で終わるけれど、「100枚の日報」を同時に投げたらどうなる?
- Makeで完全自動化が出来るのか。
- 製品マスタを更新したら、ナレッジのマスタもわざわざ手作業で変えないといけないのか?
今はまだズボラの1割しか構築できていません。
次回は大量の日報処理を検証します!
▼次回第4話でフォント別の解析検証はこちらから

▼番外編 フォント別の日報ダミーデータをAIとスプレッドシートで簡単に作成する方法

▼ノーコードツールで作るズボラDXの仮説、検証の記録はこちらにまとめています。





